Posted on September 2nd, 2010 by Brian Kelly
Introduction
This seven point checklist presents some steps that creators and managers of community digital archives might take to make sure that their data is available in the long term. It is useful for many circumstances but it will be particularly relevant to community archives that depend on third party suppliers to provide technical infrastructure.
The economic downturn and poor trading conditions mean that some technology providers are unable to continue providing the services upon which community groups have depended. Because hardware, software and services are often very tightly integrated, the failure of a technology company can be very disruptive to its customers. This is especially true if systems are proprietary and customers are ‘locked in’ to particular services, tools or data types. The key message is that community archives need to retain sufficient control of content in order that services can be moved from one service provider to another. Change brought about through insolvency is disruptive and unwelcome: the more control that a group has over content, the less disruptive it will be.
Consideration of the following seven points might help reduce disruption in the event that a content management company withdraws its services.
1. Keep the Masters
Many community groups hold a mix of photographs, sound recordings, video and text in digital form. Some of these are digital copies that have been scanned – such as old photographs, letters: some are ‘born digital’ using digital cameras or digital sound recording equipment. In every case the underlying data will be captured in one of a series of file formats. A simple rule of thumb is that a high quality ‘original’ is retained which has not been processed or edited and that the community group has direct access to this high quality ‘original’ without relying on the content management company.
2. Know What’s What
The rapid proliferation of digital content means that it can be hard to keep track of content – even in a relatively small organisation. Typically a content management company will use a database to catalogue content and then use the database to drive a Web site that makes it available to the public. So, to retain control over content community archives should keep a copy of the catalogue. The database can be complex and even when it is implemented in open source software, it can be proprietary.
The tools used to describe a collection depend on the nature of the collection. For example archives are often described in ‘Encoded Archival Description’ while an images might best be described using the ‘VRA Core’ standard. It’s useful to know a little about the standards that apply in your area.
3. There Should be a Disaster Plan
Most content management companies will have some kind of disaster plan – a backup copy which can be made available in the event of some unforeseen break of service. Good practice means that the content management company should keep multiple copies of data in multiple locations. It is reasonable for a community group to see a copy of the disaster plan and for parts of the disaster plan to be written into the contract between the contractor and the community group. You should ask for evidence that the disaster plan has been tried out and agree how quickly your data would be restored should a disaster occur. It is also reasonable to request or keep a copy of your data for safekeeping, though you may need to plan how and in what format you receive this and you may want to update it periodically.
A common approach to backups is called the ‘Grandfather – Father – Son’ approach. A complete copy is taken every month and stored remotely (Grandfather). A complete copy is taken every week but kept locally (Father) and a daily backup is made of recent changes (Son). The frequency of backups should be dictated by the frequency of changes. Ask your service provider how they approach this.
3. Agree a Succession Plan
A good content management company will also have a succession plan and be willing to involve you in this. Although it is not a happy topic, a shared understanding of rights and expectations of what should happen when either partner is no longer able maintain a contractual relationship can go a long way to reassuring both parties. This is particularly important where a hosting company is employed to deliver content which is not theirs. It is not unreasonable to include a note within the contract clearly identifying that content provided to the hosting company remains the property of the party supplying it and that should there be any break in the contract that the contractor will be obliged to return it. In reality this does not guarantee that you will get content back if a company goes into liquidation but it does secure your right to ask the administrator for it, and if that is not successful then you are then clear about your rights to use the masters and backups which have been lodged with you.
5. Know Your Rights
Rights management can be daunting but it is important to be clear when engaging a third party contractor of the limits of what they are entitled to do with content that a community archive might produce. A good content management contract is likely to give the content management company a licence to distribute content on your behalf for a given period – and it should also specify that technical parts of the service such as software are the property of the content management company. In reality this can be complicated because the community archive may itself be depending on agreements from the actual copyright holders and elements of design and coding will be shared. But so long as you are clear that the content provider will not become the owner of the content once it’s on their site, and that you can terminate their licence after appropriate notice, then it will be easier for you to pass the masters to a new company.
6. Find a Digital Preservation Service
A small number of services exist to look after data for you: either funded as part of existing infrastructure or as a service you can buy. Many local government archives and libraries are developing digital preservation facilities for their own use and might welcome an approach from a community group. Other types of partnership might also make sense: many universities now maintain digital archives for research so it might be useful to talk to a university archivist. Facilities also operate thematically – for example there is a national facility allowing archaeologists to share short reports of excavations. Image and sound libraries may also be able to provide an archival home to data or provide advice, while other services provide digital preservation on a commercial basis. In the same way publishers have started sharing some of their content to reduce their risks and risks to their clients. Having a preservation partner can be very useful for you in the short term and in the long term and will make you a lot more confident that your data will be safe even if the content management company is not around to service it.
7. Put a Copy of your Web Site in a Web Archive
There are a number of services that can make copies of online content before a supplier goes into liquidation. A free service from the British Library called the UK Web Archive exists to ‘harvest’ Web sites in the UK. It can create a simple static copy of your Web site and present this back to you under certain limitations. The UK Web Archive is free but it is based on a recommendation: you need to ask them to take a copy and need to give them permission to do so. But once you’ve given them permission they can harvest the site periodically and so build up a picture of your Web site through time. The UK Web Archive is ideal for relatively static Web sites – but is less good with sites that require passwords, which change quickly or which contain lots of dynamic content. Similar services exist such as the US-based Internet Archive have paid for services that allow users to control the harvesting of content and allow more complicated data types to be managed. Considering the ease of use and how quickly it can gather content, every community archive should consider registering with a service like this as a way to offset the risks of a supplier going into liquidation.
See the briefing paper on Web Archiving for further information [1].
The UK Web Archive is one of a number of services that can make a copy of your Website. So, in the worst case, users can be directed to a version of your site fixed at one point in time [2].
Acknowledgements
This briefing paper was written by William Kilbride of the Digital Preservation Coalition [3].
References
- Web Archiving, Cultural Heritage briefing paper no. 53, UKOLN, <http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-53/>
- UK Web Archive, <http://www.Webarchive.org.uk/>
- Digital Preservation Coalition, <http:// http://www.dpconline.org/>
Filed under: Digital Preservation, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Closing Down Blogs
There may be times when there is no longer effort available to continue to maintain a blog. There may also be occasions when a blog has fulfilled its purpose. In such cases there is a need to close the blog in a managed fashion. An example of a project blog provided by UKOLN which was closed in such a managed fashion after the project had finished is the JISC SIS Landscape Study blog. The final blog post [1] is shown below.

Figure 1: Announcement of the Closure of the JISC SIS Landscape Study Blog
The blog post makes it clear to the reader that no new posts will be published and no additional comments can be provided. Summary statistics about the blog are also provided which enables interested parties to have easy access to a summary showing the effectiveness of the blog service.
Reasons For Blog Closure
Blogs may need to be closed for a number of reasons:
- The blog author(s) may find it too time-consuming to continue to maintain a blog or to find ideas to write about or the initial enthusiasm may have waned.
- The blog author(s) may have left the organisation or have moved to other areas of work.
- The blog may not be providing an adequate return on investment.
- A blog may be withdrawn due to policy changes of managerial edict.
- The original purposes for the blog may no longer be relevant.
- Funding to continue to maintain the blog may no longer be available.
Prior to managing the closure of a blog it is advisable to ensure that the reasons for the closure of the blog are well understood and appropriate lessons are learnt.
Possible Approaches
A simple approach to closing a blog is to simple publish a final post giving an appropriate announcement, possibly containing a summary of the achievements of the blog. Comment submissions should be disabled to avoid spam comments being published. This was the approach taken by the JISC SIS Landscape Study blog [1]. [1].
A more draconian approach would be to delete the blog. This will result in the contents of the blog being difficult to find, which may be of concern if useful content has been published. If this approach has to be taken (e.g. if the blog software can no longer be supported or the service is withdrawn) it may be felt desirable to ensure that the contents of the blog are preserved.
Preserving the Contents of the Blog
A Web harvesting tool (e.g. WinTrack) could be used to copy the contents of the blog’s Web site to another location. An alternative approach would be to migrate the content using the log’s RSS feed. If this approach is taken you should ensure that an RSS feed for the complete content is used. A third approach would be to create a PDF resource of the blog site. Further advice is provided at [2].
References
- Goodbye, JISC SIS Landscape Study blog, 3 Feb 2010,
<http://blogs.ukoln.ac.uk/jisc-sis-landscape/2010/02/03/goodbye/>
- The Project Blog When The Project Is Over, UK Web Focus blog, 15 Mar 2010
<http://ukwebfocus.wordpress.com/2010/03/15/the-project-blog-when-the-project-is-over/>
Filed under: Blogs, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
About Comments On Blogs
Many blog services allow comments to be made on the blog posts. This facility is normally configurable via the blog owner’s administrator’s interface. An example of the interface in the WordPress blog is shown in Figure 1.
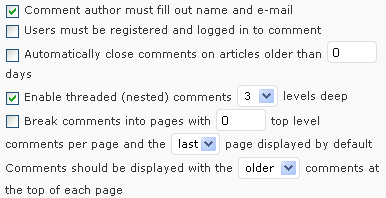
Figure 1: Administrator’s Interface for Blog Comments on WordPress Blog
The Need For A Policy
A policy on dealing with comments made to blog posts is advisable in order to handle potential problems. How should you address the following concerns, for example:
- Your comments are full of spam messages.
- Abusive comments are posted.
- Comments are posted to old messages with content which is no longer relevant.
- Excessive amount of resources are need to manage blog comments.
A blog post and subsequent discussion [1] on the UK Web Focus blog identified a number of views on policies on the moderation of blog comments which are summarised in this briefing document.
Moderated or Unmoderated Blog Comments
A simple response to such concerns might be to require all comments to be approved by the blog moderator. However this policy may hinder the development of a community based around a blog by providing a bottleneck which slows down the display of comments. In a situation in which a blog post is published late on a Friday afternoon, a blog discussion which could take place over the weekend is liked to be stifled by the delayed approval of such comments.
The UK Web Focus blog allows comments to be posted without the need for approval by the blog administrator, although a name and email address do have to be provided. It should be recognised, however, that the lack of a moderation process could mean that automated spam comments are submitted to the blog, thus limiting the effectiveness of the blog and the comment facility. The UK Web Focus blog, however, is hosted on WordPress.com which provides a comment spam filtering service called Akismet. This service has proved very effective in blocking automated spam [2].
Differing Policies for Different Types of Blogs
The policy of moderation of comments to a blog is likely to be dependent on a number of factors such as: (a) the availability of automated spam filtering tools; (b) the effort need to approve comments; (c) the effort needed to remove comments which have failed to be detected by the spam filter; (d) the purpose of the blog and (e) the likelihood that inappropriate comments may be posted.
Publicising Your Policy
It would be helpful for blog owners to make their policies on content moderation clear. An example of a policy can be seen from [3]. It may be useful for your policy to allow for changes in the light of experiences. If you require moderation of comments but find that this hinders submission of comments, you may chose to remove the moderation. However if you find that an unmoderated blog attracts large amount on unwanted comments you may decide to introduce some form of comment moderation.
References
- Moderated Comments? Closed Comments? No Thanks!, UK Web Focus blog, 15 Feb 2010,
<http://ukwebfocus.wordpress.com/2010/02/15/moderated-comments-closed-comments-no-thanks/>
- A Quarter of a Million and Counting, UK Web Focus blog, 6 Jun 2008,
<http://ukwebfocus.wordpress.com/2008/06/08/a-quarter-of-a-million-and-counting/>
- Blog Policies, UK Web Focus blog,
<http://ukwebfocus.wordpress.com/blog-policies/>
Filed under: Blogs | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
About These Documents
This document is 3 of 3 which describe best practices for consuming APIs provided by others.
Clarifying Issues
Certain issues should be clarified before use of an external API. The two key matters for elucidation are data ownership and costing. You should be clear on which items will be owned by the institution or Web author and which will be owned by a third party. You should also be clear on what the charging mechanism will be and the likelihood of change.
These matters will usually be detailed in a terms of use document and the onus is on you as a potential user to read them. If they are not explained you should contact the provider.
Understand Technology Limitations
API providers have technical limitations too and a good understanding of these will help keep your system running efficiently. Think about what will happen when the backend is down or slow and make sure that you cache remote sources aggressively. Try to build some pacing logic into your system. It’s easy to overload a server accidentally, especially during early testing. Ask the service provider if they have a version of the service that can be used during testing. Have plans for whenever an API is down for maintenance or fails. Build in timeouts, or offline updates to prevent a dead backend server breaking your application. Make sure you build in ways to detect problems. Providers are renowned for failing to provide any information as to why they are not working.
Write your application so it stores a local copy of the data so that when the feed fails its can carry on. Make this completely automatic so the system detects for itself whether the feed has failed. However, also provide a way for the staff to know that it has failed. I had one news feed exhibit not update the news for 6 months but no one noticed because there was no error state.
You will also need to be weary of your own technology limitations. Avoid overloading your application with too many API bells and whistles. Encourage and educate end users to think about end-to-end availability and response times. If necessary limit sets of results. Remember to check your own proxy, occasionally data URLs may be temporarily blocked because they come from separate sub-domains.
Other technology tips include remember to register additional API keys when moving servers.
Keep it Simple
When working with APIs it makes sense to start simple and build up. Think about the resources implications of what you are doing. For example build on top of existing libraries: Try and find a supported library for your language of choice that abstracts away from the details of the API. Wrap external APIs, don’t change them as this will be a maintenance nightmare. The exception here is if your changes can be contributed back and incorporated into the next version of the external API. APIs often don’t respond the way you would expect, make sure you don’t inadvertently make another system a required part of your own.
When working with new APIs give yourself time. Not all APIs are immediately usable. Try to ensure that the effort required to learn how to use APIs is costed into your project and ensure the associated risks are on the project’s risk list.
Some Web developers lean towards consuming lean and RESTful APIs however this may not be appropriate for your particular task. SOAP based APIs are generally seen as unattractive as they tend to take longer to develop for than RESTful ones. Client code suffers much more when any change is made to a SOAP API.
Acknowledgements
This document is based on advice provided by UKOLN’s Good APIs project. Further information is available at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
About The Best Practices For APIs Documents
The Best Practices For APIs series of briefing documents have been published for the cultural heritage sector.
The advice provided in the documents is based on resources gathered by UKOLN for the JISC-funded Good APIs project.
Further information on the Good APIs project is available from the project’s blog at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
Filed under: APIs, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
About These Documents
This document is 2 of 3 which describe best practices for consuming APIs provided by others.
Risk Management
When relying on an externally hosted service there can be some element of risk such as loss of service, change in price of a service or performance problems. Some providers may feel the need to change APIs or feeds without notice which may mean that your applications functionality becomes deprecated. This should not stop developers from using these providers but means that you should be cautious and consider providing alternatives for when a service is not (or no longer) available. Developers using external APIs should consider all eventualities and be prepared for change. One approach may be to document a risk management strategy [1] and have a redundancy solution in mind. Another might be to avoid using unstable APIs in mission critical services: bear in mind the organisational embedding of services. Developing a good working relationship with the API supplier wherever possible will allow you to keep a close eye on the current situation and the likelihood of any change.
Provide Documentation
When using an external API it is important to document your processes. Note the resources you have used to assist you, dependencies and workarounds and detail all instructions. Record any strange behaviour or side effects. Ensure you document the version of API your service/application was written for.
Bench mark the APIs you use in order to determine the level of service you can expect to get out of them.
Share Resources and Experiences
It could be argued that open APIs work because people share. Feeding back things you learn to the development community should be a usual step in the development process.
APIs providers benefit from knowing who use their APIs and how they use them. You should make efforts provide clear, constructive and relevant feedback on the code through bug reports), usability and use of APIs you engage with. If it is open source code it should be fairly straightforward to improve an API to meet your needs and in doing so offer options to other users. If you come across a difficulty that the documentation failed to solve then either update the documentation, contact the provider or blog about your findings (and tell the provider). Publish success stories and provide workshops to showcase what has and can been achieved. Sharing means that you can save others time. The benefits are reciprocal. As one developed commented:
“If you find an interesting or unexpected use of a method, or a common basic use which isn’t shown as an example already, comment on its documentation page. If you find that a method doesn’t work where it seems that it should, comment on its documentation page. If you are confused by documentation but then figure out the intended or correct meaning, comment on its documentation page.”
Sharing should also be encouraged internally. Ensure that all the necessary teams in your institution know which APIs are relevant to what services, and that the communications channels are well used. Developers should be keeping an eye on emerging practice; what’s ‘cool’ etc. Share this with your team.
Feedback how and why you are using the API, often service providers are in the dark about who is using their service and why, and being heard can help guide the service to where you need it to be, as well as re-igniting developer interest in pushing on the APIs.
Respect
When using someone else’s software it is important to respect the terms of use. This may mean making efforts to minimise load on the API providers servers or limiting the number of calls made to the service (e.g. by using a local cache or returned data, only refreshed once a given time period has expired). Using restricted examples while developing and testing is a good way to avoid overload the provider’s server. There may also be sensitivity or IPR issues relating to data shared.
Note that caching introduces technical issues. Latency or stale data could be a problem if there is caching.
Acknowledgements
document is based on advice provided by UKOLN’s Good APIs project. Further information is available at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
References
- Using the Risks and Opportunities Framework, UKOLN briefing document no. 68, <http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-68/>
About The Best Practices For APIs Documents
The Best Practices For APIs series of briefing documents have been published for the cultural heritage sector.
The advice provided in the documents is based on resources gathered by UKOLN for the JISC-funded Good APIs project.
Further information on the Good APIs project is available from the project’s blog at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
Filed under: APIs, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
About These Documents
This document is 1 of 3 which describe best practices for consuming APIs provided by others.
Be Careful In Selecting The APIs
Choose the APIs you use carefully. You can find potential APIs by signing up to RSS feeds, registering for email notifications for when new APIs are released, checking forums and searching API directories.
A decision on using an API can be made for a number of reasons (it’s the only one available, we’ve been told to use it, etc.) but developers should check the following:
- That it is the best fit for your needs. There may well be other APIs out there that are more appropriate. Good research is very important as it is more than likely that for popular APIs someone has probably done the hard work and produced a library for your language of choice. That said it is possible that you might have to compromise.
- What the API does. Spend some time finding out.
- How good the documentation is. Check that the documentation correctly matches the API being used. Request sample application code that communicates with the API. Initially commercial software vendors were reluctant to provide good well documented services often only provided simple data transaction services. Good documentation is now accepted as critical.
- That the APIs is connected to a functional description, i.e. an overall description of the function of the entire application.
- That there is a dialogue with the developers such as a forum or email list. This will help establish if there is continued support for bug fixes etc.
- That this API does not clash with each others you are using and will be able to ‘keep in step’.
- That it is a stable API. APIs that are still evolving are liable to change.
- How reliable it is? Some API providers have a better reputation than others.
- How popular it is? Popular APIs tend to have an active user community.
- If it is still managed? APIs which are not currently managed are unlikely to be supported.
- If selecting a product with APIs offered as part of the package ensure you evaluate the APIs too.
- What language has it been coded in?
- Whether a roadmap explaining likely directions of future developments is available.
Study various information sources for each potential API. These could include tutorials, online forums, mailing lists and online magazine articles offering an overview or introduction to the technology as well as the official sources of information. There are also a number of user satisfaction services available such as getsatisfaction [1] or uservoice [2]. The JDocs Web site [3] maintains a searchable collection of Java related APIs and allows use comments to be added to the documentation. You may find that others have encountered problems with a particular API.
Once you have chosen an API it may be appropriate to write a few basic test cases before you begin integration.
If you’re not paying for an API then make sure that the API is part of the provider’s core services which they use themselves. If the provider produces a custom service just for you then if they’re not being paid they have no incentive to keep that API up to date.
As one developer advised:
“When using APIs from others, do a risk assessment. Think about what you want for the future of the application (or part thereof) that will depend on the API, assess its value and the cost of losing it unexpectedly during its intended lifespan, guesstimate how likely it will be that the API will change significantly or become unavailable /useless in that time span. Think about an exit strategy. Consider intermediary libraries if they exist (e.g. for mapping) to allow a ready switch from one API”
Acknowledgements
This document is based on advice provided by UKOLN’s Good APIs project. Further information is available at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
References
- Getsatisfaction, <http://getsatisfaction.com/>
- Uservoice, <http://uservoice.com/>
- JDocs, <http://www.jdocs.com/>
About The Best Practices For APIs Documents
The Best Practices For APIs series of briefing documents have been published for the cultural heritage sector.
The advice provided in the documents is based on resources gathered by UKOLN for the JISC-funded Good APIs project.
Further information on the Good APIs project is available from the project’s blog at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
Filed under: APIs | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Make Sure the API Works
Make your API scalable (i.e. able to cope with a high number of hits), extendable and design for updates. Test your APIs as thoroughly as you would test your user interfaces and where relevant, ensure that it returns valid XML (i.e. no missing or invalid namespaces, or invalid characters).
Embed your API in a community and use them to test it. Use your own API in order to experience how user friendly it is.
As one developer commented:
“Once you have a simple API, use it. Try it on for size and see what works and what doesn’t. Add the bits you need, remove the bits you don’t, change the bits that almost work. Keep iterating till you hit the sweet spot.”
Obtain Feedback On Your API
Include good error logging, so that when errors happen, the calls are all logged and you will be able to diagnose what went wrong:
“Fix your bugs in public”
If possible, get other development teams/projects using your API early to get wider feedback than just the local development team. Engage with your API users and encourage community feedback.
Provide a clear and robust contact mechanism for queries regarding the API. Ideally this should be the name of an individual who could potentially leave the organisation.
Provide a way for users of the API to sign up to a mailing list to receive prior notice of any changes.
As one developer commented:
“An API will need to evolve over time in response to the needs of the people attempting to use it, especially if the primary users of the API were not well defined to begin with.”
Error Handling
Once an API has been released it should be kept static and not be changed. If you do have to change an API maintain backwards compatibility. Contact the API users and warn then well in advance and ask them to get back to you if changes affect the services they are offering. Provide a transitional frame-time with deprecated APIs support. As one developer commented:
“The development of a good set of APIs is very much a chicken-and-egg situation – without a good body of users, it is very hard to guess at the perfect APIs for them, and without a good set of APIs, you cannot gather a set of users. The only way out is to understand that the API development cannot be milestoned and laid-out in a precise manner; the development must be powered by an agile fast iterative method and test/response basis. You will have to bribe a small set of users to start with, generally bribe them with the potential access to a body of information they could not get hold of before. Don’t fall into the trap of considering these early adopters as the core audience; they are just there to bootstrap and if you listen too much to them, the only audience your API will become suitable for is that small bootstrap group.”
Logging the detail of API usage can help identify the most common types of request, which can help direct optimisation strategies. When using external APIs it is best to design defensively: e.g. to cater for situations when the remote services are unavailable or the API fails.
Consider having a business model in place so that your API remains sustainable. As one developer commented:
“Understand the responsibility to users which comes with creating and promoting APIs: they should be stable, reliable, sustainable, responsive, capable of scaling, well-suited to the needs of the customer, well-documented, standards-based and backwards compatible.”
Acknowledgments
This document is based on advice provided by UKOLN’s Good APIs project. Further information is available at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
About The Best Practices For APIs Documents
The Best Practices For APIs series of briefing documents have been published for the cultural heritage sector.
The advice provided in the documents is based on resources gathered by UKOLN for the JISC-funded Good APIs project.
Further information on the Good APIs project is available from the project’s blog at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
Filed under: APIs, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Provide Documentation
Although a good API should be, by its very nature, intuitive and theoretically not need documentation it is good practice to provide clear useful documentation and examples for prospective developers. This documentation should be well written, clear and full. Inaccurate, inappropriate or documentation of your API is the easiest way to lose users.
Developers should give consideration to including most, if not all, of the following:
- Information on and links to related functions.
- Worked examples and suggestions for use. The examples should be easy to clone, from different programming languages.
- Case studies. Real world examples (e.g. PHP Java Ruby, python etc.)
- Demos – if you want to entice someone to use your API you need good examples that can be re-used quickly. Provide a ‘Getting started’ guide.
- Tutorials and walkthroughs.
- Documentation for less technical developers.
- A trouble shooting guide.
- A reference client/server system that people can code against for testing and possibly access to libraries and example code.
- Opportunities for user feedback, on both the documentation and the API itself
- Migration tips.
- A clear outline of the terms of service of the API. e.g. This is an experimental service, we may change or withdraw this at any time” or “We guarantee to keep this API running until at least January 2012″.
- Any ground rules.
- An appendix with design decisions. Knowing why an API developed the way it did can often help a new developer understand the interface more rapidly.
Good documentation is effectively a roadmap of the API that helps to orientate a new developer quickly. It will allow others to pick up and run with your API. Providing it on release of your API will result in less time spent taking support calls.
Other suggestions include using a mechanism that allows automatic extraction of the comments, such as Javadoc and providing inline documentation that produces Intellisense-type context-sensitive help.
Error Handling
Providing good error handling is essential if you want to give the developers using your API an opportunity to correct their mistake. Error messages should be clear and concise and pitched at the appropriate. Messages such as “Input has failed” are highly unhelpful and unfortunately fairly common. Avoid:
- Inconsistency (e.g. different variable order in similar methods).
- Over-general error reporting (a single exception object covering a number of very different possible errors).
- Over-complicated request payload – having to send a complex session object as part of each Web service call.
Log API traffic with as much context as possible to deal with resolution of errors. Provide permanently addressable status and changelog pages for your API; if the service or API goes down for any reason, these two pages must still be visible, preferably with why things are down.
Provide APIs In Different Languages
A simple Web API is usually REST/HTTP based, with XML delivery of a simple schema e.g. RSS. You may want to offer toolkits for different languages and support a variety of formats (e.g. SOAP, REST, JSON etc.).
Try to provide APIs in XML format then it can also be read by other devices such as kiosks and LED displays. Making returned data available in a number of format (e.g. XML, JSON, PHP encoded array) it saves developers a lot of wasted time parsing XML to make an array.
Provide sample code that uses API in different languages. Try to be general where possible so that one client could be written against multiple systems (even if full functionality is not available without specialization).
For database APIs, provide a variety of output options – different metadata formats and/or levels of detail.
Acknowledgments
This document is based on advice provided by UKOLN’s Good APIs project. Further information is available at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
Filed under: APIs | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Seek To Follow Standards
It is advisable to follow standards where applicable. If possible it makes sense to piggy-back on to accepted Web-oriented standards and use well know standards from international authorities: IEEE, W3C, OAI or from successful, established companies. You could refer to the W3C Web Applications Working Group. Where an existing standard isn’t available or appropriate then be consistent, clear, and well-documented.
Although standards are useful and important you should be aware that some standards may be difficult to interpret or not openly available. Understanding the context within which one is operating, the contexts for which particular standards were designed and/or are applicable/appropriate and on that basis making informed decisions about the deployment of those standards.
Use Consistent Naming Structures
Use consistent, self explanatory method names and parameter structures, explicit name for functions and follow naming conventions. For example, similar methods should have arguments in the same order. Developers who fail to use naming conventions may find that their code is difficult to understand, other developers find it difficult to integrate and so go elsewhere. Naming decisions are important and there can be multilingual and cultural issues with understanding names and functionality so check your ideas with other developers.
Make The API Easier To Access
External developers are important, they can potentially add value to your service so you need to make it easy for them to do so and make sure that there is a low barrier to access. The maximum entry requirements should be a login (username and password) which then emails out a link.
If it is for a specific institution and contains what could be confidential information then it will need to contain some form of authentication that can be transmitted in the request.
If you need to use a Web API key make it straightforward to use. You should avoid the bottle neck of user authorisation, an overly complex or non-standard authentication process. One option is publish a key that anyone can use to make test API calls so that people can get started straight away. Another is to provide a copy of the service for developers to use that is separate from your production service. You could provide a developer account, developers will need to test your API so try to be amenable. If you release an open API then it needs to be open.
If possible seek to support Linked Data. Also publish resources that reflect a well-conceived domain model and use URIs that reflect the domain model.
Let Developers Know the API Exists
Making sure that potential users know about your API is vital:
- Contact your development community using email, RSS, Twitter and any other communication mechanisms you have available.
- Write about your API on developer forums. Make sure that you follow this up by having some of your developers monitoring the forum and answering questions.
- If appropriate publish API on Programmable Web.
- Blog about your API.
- Make yourself known. Twitter and chat about APIs with other developers you’ll get a name as a developer and people will be interested when you release APIs.
- Add a “developers” link in the footer of your Web site. If you have released a number of APIs then the developer section of your site a comprehensive microsite with useful documentation.
- Link to working third-party applications that use your API, or third-party libraries that access it.
Version Control
Deal with versioning from the start. Ensure that you add a version number to all releases and keep developers informed. Either commit to keeping APIs the same or embed in version numbers so that applications can continue to use earlier versions of APIs if they change. You could use SourceForge or a version repository to assist.
Acknowledgments
This document is based on advice provided by UKOLN’s Good APIs project. Further information is available at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
Filed under: APIs | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
About The Best Practices For APIs Documents
This document is the first in a series of four briefing documents which provide advice on the planning processes for the creation of APIs.
The Importance of Planning
As with other activities, design of APIs projects requires effective planning. Rather than just adding an API to an existing service/software and moving straight into coding developers should consider planning, resourcing and managing the creation, release and use of APIs. They need to check that there isn’t already a similar API available before gathering data or developing something new. Then spend time defining requirements and making sure they consider the functionality they want the user to access.
Although formal planning may not always be appropriate in some ‘quick and dirty’ projects some form of prototyping can be very helpful. Some areas that might need consideration are scale, weighing up efficiency and granularity.
Authors who change their specification or don’t produce an accurate specification in the first place may find themselves in trouble later on in a project.
Gathering Requirements
Talking to your users and asking what they would like is just as important in API creation as user interface creation. At times it may be necessary to second-guess requirements but if you have the time it is always more efficient to engage with potential users. Technical people need to ask the user what they are actually after. You could survey a group of developers or ask members of your team.
“The development of a good set of APIs is very much a chicken-and-egg situation – without a good body of users, it is very hard to guess at the perfect APIs for them, and without a good set of APIs, you cannot gather a set of users. The only way out is to understand that the API development cannot be milestoned and laid-out in a precise manner; the development must be powered by an agile fast iterative method and test/response basis. You will have to bribe a small set of users to start with, generally bribe them with the potential access to a body of information they could not get hold of before. Don’t fall into the trap of considering these early adopters as the core audience; they are just there to bootstrap and if you listen too much to them, the only audience your API will become suitable for is that small bootstrap group.”
Make The APIs Useful
When creating an API look at it both from your own perspective and from a user’s perspective, offer something that can add value or be used in many different ways. One option is to consider developing a more generic application from the start as it will open up the possibilities for future work. Anticipate common requests and optimise your API accordingly. Open up the functions you’re building.
Get feedback from others on how useful it is. Consider different requirements of immediate users and circumstances against archival and preservation requirements.
Collaborating on any bridges and components is a good way to help developers tap into other team knowledge and feedback.
Keep It Simple
The adage “complex things tend to break and simple things tend to work” has been fairly readily applied to the creation of Web APIs. Although simplicity is not always the appropriate remedy, for most applications it is the preferred approach. APIs should be about the exposed data rather than application design.
Keep the specifications simple, especially when you are starting out. Documenting what you plan to do will also help you avoid scope creep. Avoid having too many fields and too many method calls. Offer simplicity, or options with simple or complex levels.
Developers should consider only adding API features if there is a provable extension use case. One approach might be to always ask “do we actually need to expose this via our API?“.
Make It Modular
It is better to create an API that has one function and does it well rather than an API that does many things. Good programming is inherently modular. This allows for easier reuse and sustains a better infrastructure.
The service should define itself and all methods available. This means as you add new features to the API, client libraries can automatically provide interfaces to those methods without needing new code.
As one developer commented:
“It is not enough to put a thin layer on top of a database and provide a way to get data from each table separately. Many common pieces of information can only be retrieved in a useful way by relating data between tables. A decent API would seek to make retrieving commonly-related sets of data easy.”
Acknowledgments
This document is based on advice provided by UKOLN’s Good APIs project. Further information is available at <http://blogs.ukoln.ac.uk/good-apis-jisc/>.
Filed under: APIs, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
What Is Podcasting?
Podcasting has been described as “a method of publishing files to the internet, often allowing users to subscribe to a feed and receive new files automatically by subscription, usually at no cost.” [1].
Podcasting is a relatively new phenomena becoming popular in late 2004. Some of the early adopters regard Podcasting as a democratising technology, allowing users to easily create and publish their own radio shows which can be easily accessed within the need for a broadcasting infrastructure. From a technical perspective, Podcasting is an application of the RSS 2.0 format [2]. RSS can be used to syndicate Web content, allowing Web resources to be automatically embedded in third party Web sites or processed by dedicated RSS viewers. The same approach is used by Podcasting, allowing audio files (typically in MP3 format) to be automatically processed by third party applications – however rather than embedding the content in Web pages, the audio files are transferred to a computer hard disk or to an MP3 player – such as an iPod.
The strength of Podcasting is the ease of use it provides rather than any radical new functionality. If, for example, you subscribe to a Podcast provided by the BBC, new episodes will appear automatically on your chosen device – you will not have to go to the BBC Web site to see if new files are available and then download them.
Note that providing MP3 files to be downloaded from Web sites is sometimes described as Podcasting, but the term strictly refers to automated distribution using RSS.
What Can Podcasting Be Used For?
There are several potential applications for Podcasting in an educational context:
- Maximising the impact of talks by allowing seminars, lectures, conference presentations, etc. to be listened to by a wider audience.
- Recording of talks allowing staff to easily access staff developments sessions and meetings as a revision aid, to catch up on missed lectures, etc.
- Automated conversion of text files, email messages, RSS feeds, etc. to MP3 format, allowing the content to be accessed on mobile MP3 players.
- Maximising the impact of talks by allowing seminars, lectures, conference presentations, etc. to be listened to by a wider audience.
- Recordings of meetings to provide access for people who could not attend.
- Enhancing the accessibility of talks to people with disabilities.
Possible Problems
Although there is much interest in the potential for Podcasting, there are potential problem areas which will need to be considered:
- Recording lectures, presentations, etc. may infringe copyright or undermine the business model for the copyright owners.
- Making recordings available to a wider audience could mean that comments could be taken out of context or speakers may feel inhibited when giving presentations.
- The technical quality of recordings may not be to the standard expected.
- Although appealing to the publisher, end users may not make use of the Podcasts.
It would be advisable to seek permission before making recordings or making recordings available as Podcasts.
Podcasting Software
Listening To Podcasts
It is advisable to gain experiences of Podcasting initially as a recipient, before seeking to create Podcasts. Details of Podcasting software is given at [3] and [4]. Note that support for Podcasts in iTunes v. 5 [5] has helped enhance the popularity of Podcasts. You should note that you do not need a portable MP3 player to listen to Podcasts – however the ability to listen to Podcasts while on the move is one of its strengths.
Creating Podcasts
When creating a Podcast you first need to create your MP3 (or similar) audio file. Many recording tools are available, such as the open source Audacity software [6]. You may also wish to make use of audio editing software to edit files, include sound effects, etc.
You will then need to create the RSS file which accompanies your audio file, enabling users to subscribe to your recording and automate the download. An increasing number of Podcasting authoring tools and Web services are being developed [7] .
References
- Podcasting, Wikipedia,
<http://en.wikipedia.org/wiki/Podcasting>
- RSS 2.0, Wikipedia,
<http://en.wikipedia.org/wiki/Really_Simple_Syndication>
- iPodder Software,
<http://www.ipodder.org/directory/4/ipodderSoftware>
- iTunes – Podcasting,
<http://www.apple.com/podcasting/>
- Podcasting Software (Clients), Podcasting News,
<http://www.podcastingnews.com/topics/Podcast_Software.html>
- Audacity,
<http://audacity.sourceforge.net/>
- Podcasting Software (Publishing), Podcasting News,
<http://www.podcastingnews.com/topics/Podcasting_Software.html>
Filed under: Web 2.0 | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Background
This document provides an introduction to microformats, with a description of what microformats are, the benefits they can provide and examples of their usage. In addition the document discusses some of the limitations of microformats and provides advice on best practices for use of microformats.
What Are Microformats?
“Designed for humans first and machines second, microformats are a set of simple, open data formats built upon existing and widely adopted standards. Instead of throwing away what works today, microformats intend to solve simpler problems first by adapting to current behaviors and usage patterns (e.g. XHTML, blogging).” [1].
Microformats make use of existing HTML/XHTML markup: Typically the <span> and <div> elements and class attribute are used with agreed class name (such as vevent, dtstart and dtend to define an event and its start and end dates). Applications (including desktop applications, browser tools, harvesters, etc.) can then process this data.
Examples Of Microformats
Popular examples of microformats include:
- hCard: Markup for contact details such as name, address, email, phone no., etc. Browser tools such as Tails Export [2] allow hCard microformats in HTML pages to be added to desktop applications (e.g. MS Outlook).
- hCalendar: Markup for events such as event name, date and time, location, etc. Browser tools such as Tails Export and Google hCalendar [3] allow hCalendar microformats in HML pages to be added to desktop calendar applications (e.g. MS Outlook) and remote calendaring services such as Google Calendar.
An example which illustrates commercial takeup of the hCalendar microformat is Yahoo’s Upcoming service [4]. This service allows registered users to provide information about events. This information is stored in hCalendar format, allowing the information to be easily added to a local calendar tool.
Limitations Of Microformats
Microformats have been designed to make use of existing standards such as HTML. They have also been designed to be simple to use and exploit. However such simplicity means that microformats have limitations:
- Possible conflicts with the Semantic Web approach: The Semantic Web seeks to provide a Web of meaning based on a robust underlying architecture and standards such as RDF. Some people feel that the simplicity of microformats lacks the robustness promised by the Semantic Web.
- Governance: The definitions and ownership of microformats schemes (such as hCard and hCalendar) is governed by a small group of microformat enthusiasts.
- Early Adopters: There are not yet well-established patterns of usage, advice on best practices or advice for developers of authoring, viewing and validation tools.
Best Practices for Using Microformats
Despite their limitations microformats can provide benefits to the user community. However in order to maximise the benefits and minimise the risks associated with using microformats it is advisable to make use of appropriate best practices. These include:
- Getting it right from the start: Seek to ensure that microformats are used correctly. Ensure appropriate advice and training is available and that testing is carried out using a range of tools. Discuss the strengths and weaknesses of microformats with your peers.
- Having a deployment strategy: Target use of microformats in appropriate areas. For example, simple scripts could allow microformats to be widely deployed, yet easily managed if the syntax changes.
- Risk management: Have a risk assessment and management plan which identifies possible limitations of microformats and plans in case changes are needed [5].
References
- About Microformats, Microformats.org,
<http://microformats.org/about/>
- Tails Export: Overview, Firefox Addons,
<https://addons.mozilla.org/firefox/2240/>
- Google hCalendar,
<http://greasemonkey.makedatamakesense.com/google_hcalendar/>
- Upcoming, Yahoo!,
<http://upcoming.yahoo.com/>
- Risk Assessment For The IWMW 2006 Web Site, UKOLN,
<http://www.ukoln.ac.uk/web-focus/events/workshops/webmaster-2006/risk-assessment/#microformats>
Filed under: Web 2.0 | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Background
This briefing document provides advice for Web authors, developers and policy makers who are considering making use of Web 2.0 services which are hosted by external third party services. The document describes an approach to risk assessment and risk management which can allow the benefits of such services to be exploited, whilst minimising the risks and dangers of using such services.
Note that other examples of advice are also available [1] [2].
About Web 2.0 Services
This document covers use of third party Web services which can be used to provide additional functionality or services without requiring software to be installed locally. Such services include:
- Search facilities, such as Google University Search and Atomz.
- Social bookmarking services, such as del.icio.us.
- Wiki services, such as WetPaint.
- Usage analysis services, such Google Analytics and SiteMeter.
- Chat services such as Gabbly and ToxBox.
Advantages and Disadvantages
Advantages of using such services include:
- May not require scarce technical effort.
- Facilitates experimentation and testing.
- Enables a diversity of approaches to be taken.
Possible disadvantages of using such services include:
- Potential security and legal concerns e.g. copyright, data protection, etc.
- Potential for data loss or misuse.
- Reliance on third parties with whom there may be no contractual agreements.
Risk Management and Web 2.0
Examples of risks and risk management approaches are given below.
| Risk |
Assessment |
Management |
| Loss of service (e.g. company becomes bankrupt, closed down, …) |
Implications if service becomes unavailable.
Likelihood of service unavailability. |
Use for non-mission critical services.
Have alternatives readily available.
Use trusted services. |
| Data loss |
Likelihood of data loss.
Lack of export capabilities. |
Evaluation of service.
Non-critical use.
Testing of export. |
Performance problems.
Unreliability of service. |
Slow performance |
Testing.
Non-critical use. |
| Lack of interoperability. |
Likelihood of application lock-in.
Loss of integration and reuse of data. |
Evaluation of integration and export capabilities. |
| Format changes |
New formats may not be stable. |
Plan for migration or use on a small-scale. |
| User issues |
User views on services. |
Gain feedback. |
Note that in addition to risk assessment of Web 2.0 services, there is also a need to assess the risks of failing to provide such services.
Example of a Risk Management Approach
A risk management approach [3] was taken to use of various Web 2.0 services on the Institutional Web Management Workshop 2009 Web site.
- Use of established services:
- Google and Google Analytics are used to provide searching and usage reports.
- Alternatives available:
- Web server log files can still be analysed if the hosted usage analysis services become unavailable.
- Management of services:
- Interfaces to various services were managed to allow them to be easily changed or withdrawn.
- User Engagement:
- Users are warned of possible dangers and invited to engage in a pilot study.
- Learning:
- Learning may be regarded as the aim, not provision of long term service.
<!–
- Agreements:
- An agreement has been made for the hosting of a Chatbot service.
–>
References
- Checklist for assessing third-party IT services, University of Oxford,
<http://www.oucs.ox.ac.uk/internal/3rdparty/checklist.xml>
- Guidelines for Using External Services, University of Edinburgh,
<https://www.wiki.ed.ac.uk/download/attachments/8716376/GuidelinesForUsingExternalWeb2.0Services-20080801.pdf?version=1>
- Risk Assessment, IWMW 2006, UKOLN,
<http://iwmw.ukoln.ac.uk/iwmw2009/risk-assessment/>
Filed under: Needs-checking, Risk Management | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
About this document
Performance and reliability are the principal criteria for selecting software. In most procurement exercises however, price is also a determining factor when comparing quotes from multiple vendors. Price comparisons do have a role, but usually not in terms of a simple comparison of purchase prices. Rather, price tends to arise when comparing “total cost of ownership” (TCO), which includes both the purchase price and ongoing costs for support (and licence renewal) over the real life span of the product. This document provides tips about selecting open source software.
The Top Tips
- Consider The Reputation
- Does the software have a good reputation for performance and reliability? Here, word of mouth reports from people whose opinion you trust is often key. Some open source software has a very good reputation in the industry, e.g. Apache Web server, GNU Compiler Collection (GCC), Linux, Samba, etc. You should be comparing “best of breed” open source software against its proprietary peers. Discussing your plans with someone with experience using open source software and an awareness of the packages you are proposing to use is vital.
- Monitor Ongoing Effort
- Is there clear evidence of ongoing effort to develop the open source software you are considering? Has there been recent work to fix bugs and meet user needs? Active projects usually have regularly updated web pages and busy development email lists. They usually encourage the participation of those who use the software in its further development. If everything is quiet on the development front, it might be that work has been suspended or even stopped.
- Look At Support For Standards And Interoperability
- Choose software which implements open standards. Interoperability with other software is an important way of getting more from your investment. Good software does not reinvent the wheel, or force you to learn new languages or complex data formats.
- Is There Support From The User Community?
- Does the project have an active support community ready to answer your questions concerning deployment? Look at the project’s mailing list archive, if available. If you post a message to the list and receive a reasonably prompt and helpful reply, this may be a sign that there is an active community of users out there ready to help. Good practice suggests that if you wish to avail yourself of such support, you should also be willing to provide support for other members of the community when you are able.
- Is Commercial Support Available?
- Third party commercial support is available from a diversity of companies, ranging from large corporations such as IBM and Sun Microsystems, to specialist open source organizations such as Red Hat and MySQL, to local firms and independent contractors. Commercial support is most commonly available for more widely used products or from specialist companies who will support any product within their particular specialism.
- Check Versions
- When was the last stable version of the software released? Virtually no software, proprietary or open source, is completely bug free. If there is an active development community, newly discovered bugs will be fixed and patches to the software or a new version will be released. For enterprise use, you need the most recent stable release of the software, be aware that there may have been many more recent releases in the unstable branch of development. There is, of course, always the option of fixing bugs yourself, since the source code of the software will be available to you. But that rather depends on your (or your team’s) skill set and time commitments.
- Think Carefully About Version 1.0
- Open source projects usually follow the “release early and often” motto. While in development they may have very low version numbers. Typically a product needs to reach its 1.0 release prior to being considered for enterprise use. (This is not to say that many pre-”1.0″ versions of software are not very good indeed, e.g. Mozilla’s 0.8 release of its Firefox browser).
- Check The Documentation
- Open source software projects may lag behind in their documentation for end users, but they are typically very good with their development documentation. You should be able to trace a clear history of bug fixes, feature changes, etc. This may provide the best insight into whether the product, at its current point in development, is fit for your purposes.
- Do You Have The Required Skill Set?
- Consider the skill set of yourself and your colleagues. Do you have the appropriate skills to deploy and maintain this software? If not, what training plan will you put in place to match your skills to the task? Remember, this is not simply true for open source software, but also for proprietary software. These training costs should be included when comparing TCOs for different products.
- What Licence Is Available?
- Arguably, open source software is as much about the license as it is about the development methodology. Read the licence. Well-known licenses such as the General Public License (GPL) and the Lesser General Public License (LGPL) have well defined conditions for your contribution of code to the ongoing development of the software or the incorporation of the code into other packages. If you are not familiar with these licenses or with the one used by the software you are considering, take the time to clarify conditions of use.
- What Functionality Does The Software Provide?
- Many open source products are generalist and must be specialised before use. Generally speaking the more effort required to specialise a product, the greater is its generality. A more narrowly focused product will reduce the effort require to deploy it, but may lack flexibility. An example of the former is GNU Compiler Collection (GCC), and an example of the latter might be Evolution email client, which works well “out of the box” but is only suitable for the narrow range of tasks for which it was intended.
Further Information
Acknowledgements
This document was written by Randy Metcalfe of OSS Watch. OSS Watch is the open source software advisory service for UK higher and further education. It provides neutral and authoritative guidance on free and open source software, and about related open standards.
The OSS Watch Web site ia available at http://www.oss-watch.ac.uk/.
Filed under: Needs-checking, Software | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Introduction
A Risks and Opportunities Framework for exploiting the potential of innovation such as the Social Web has been developed by UKOLN [1]. This approach has been summarised in a briefing document [2] [2]. This briefing document provides further information on the processes which can be used to implement the framework.
The Risks and Opportunities Frame
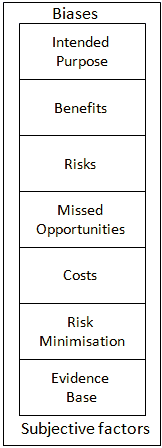 The Risks and Opportunities Framework aims to facilitate discussions and decision-making when use of innovative services is being considered.
The Risks and Opportunities Framework aims to facilitate discussions and decision-making when use of innovative services is being considered.
As illustrated, a number of factors should be addressed in the planning processes for the use of innovative new services, such as use of the Social Web. Further information on these areas is given in [2].
Critical Friends
A ‘Critical Friends’ approach to addressing potential problems and concerns in the development of innovative services is being used to JISC to support its funding calls. As described on the Critical Friends Web site [3]:
The Critical Friend is a powerful idea, perhaps because it contains an inherent tension. Friends bring a high degree of unconditional positive regard. Critics are, at first sight at least, conditional, negative and intolerant of failure.
Perhaps the critical friend comes closest to what might be regarded as ‘true friendship’ – a successful marrying of unconditional support and unconditional critique.
The Critical Friends Web site provides a set of Effective Practice Guidelines [4] for Critical Friends, Programme Sponsors and Project Teams.
A successful Critical Friends approach will ensure that concerns are raised and addressed in an open, neutral and non-confrontational way.
Risk Management and Minimisation
It is important to acknowledge that there may be risks associated with the deployment of new services and to understand what those risks might be. As well as assessing the likelihood of the risks occurring and the significance of such risks there will be a need to identify ways in which such risks can be managed and minimised.
It should b noted that risk management approaches might include education, training and staff development as well technical development. It should also be recognised that if may be felt that risks are sometimes worth taking.
Gathering Evidence
The decision-making process can be helped if it is informed by evidence. Use of the Risks and Opportunities Framework is based on documentation of intended uses of the new service, perceived risks and benefits, costs and resource implications and approaches for risk minimisation. Where possible the information provided in the documentation should be linked to accompanying evidence.
In a rapidly changing technical environment with changing user needs and expectations there will be a need to periodically revisit evidence in order to ensure that significant changes have not taken place which may influence decisions which have been made.
Using The Framework
A template for use of the framework is summarised below:
| Area |
Summary |
Evidence |
| Intended Use |
Specific examples of the intended use of the service. |
Examples of similar uses by one’s peers. |
| Benefits |
Description of the benefits for the various stakeholders. |
Evidence of benefits observed in related uses. |
| Risks |
Description of the risks for the various stakeholders. |
Evidence of risks entailed in related uses. |
| Missed Opportunities |
Description of the risks in not providing the service. |
Evidence of risks entailed by peers who failed to innovate. |
| Costs |
Description of the costs for the various stakeholders. |
Evidence of costs encountered by one’s peers. |
| Risk Minimisation |
Description of the costs for the various stakeholders. |
Evidence of risk minimisation approaches taken by others. |
References
- Time To Stop Doing and Start Thinking: A Framework For Exploiting Web 2.0 Services, Kelly, B., Museums and the Web 2009: Proceedings,
<http://www.ukoln.ac.uk/web-focus/papers/mw-2009/>
- A Risks and Opportunities Framework for the Social Web, UKOLN Cultural Heritage briefing document no. 67,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-67/>
- Critical Friends Network,
<http://www.critical-friends.org/>
- Guidelines for Effective Practice, Critical Friends Network,
<http://www.critical-friends.org/daedalus/cfpublic.nsf/guidelines?openform>
Filed under: Needs-checking, Risk Management | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Introduction
In today’s environment of rapid technological innovation and changing user expectations coupled with financial pressures it is no longer possible for cultural heritage organisations to develop networked services without being prepared to take some risks [1]. The challenge is how to assess such risks prior to making policy decision as to whether the organisation is willing to take such risks.
This briefing document described a framework which aims to support the decision-making process in the content of possible use of the Social Web.
Assessing Risks
Risks should be assessed within the context of use. This context will include the intended purpose of the service, the benefits which the new service are perceived to bring to the various stakeholders and the costs and other resource implications of the deployment and use of the service.
Assessing Missed Opportunities
In addition to assessing the risks of use of a new service there is also a need to assess the risk of not using the new service – the missed opportunity costs. Failing to exploit a Social Web service could result in a loss of a user community or a failure to engage with new potential users. It may be the risks of failing to innovate could be greater than the risks of doing nothing.
Risk Management and Minimisation
It is important to acknowledge that there may be risks associated with the deployment of new services and to understand what those risks might be. As well as assessing the likelihood of the risks occurring and the significance of such risks there will be a need to identify ways in which such risks can be managed and minimised.
It should b noted that risk management approaches might include education, training and staff development as well technical development. It should also be recognised that if may be felt that risks are sometimes worth taking.
The Risks and Opportunities Framework
The Risks and Opportunities Framework was first described in a paper on “Time To Stop Doing and Start Thinking: A Framework For Exploiting Web 2.0 Services” presented at the Museums and the Web 2009 conference [2] and further described at [3].
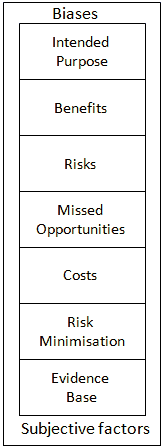 This framework aims to facilitate discussions and decision-making when use of Social Web service is being considered.
This framework aims to facilitate discussions and decision-making when use of Social Web service is being considered.
The components of the framework are:
- Intended use
- Rather than talking about services in an abstract context (“shall we have a Facebook page“) specific details of the intended use should be provided.
- Perceived benefits
- A summary of the perceived benefits which use of the Social Web service are expected to provide should be documented.
- Perceived risks
- The perceived risks which use of the Social Web service may entail should be documented.
- Missed opportunities
- A summary of the missed opportunities and benefits which a failure to make use of the Social Web service should be documented.
- Costs
- A summary of the costs and other resource implications of use of the service should be documented.
- Risk minimisation
- Once the risks have been identified and discussed approaches to risk minimisation should be documented.
- Evidence base
- Evidence which back up assertions made in use of the framework.
References
- Risk Management InfoKit, JISC infoNET,
<http://www.jiscinfonet.ac.uk/InfoKits/risk-management>
- Time To Stop Doing and Start Thinking: A Framework For Exploiting Web 2.0 Services, Kelly, B., Museums and the Web 2009: Proceedings,
<http://www.ukoln.ac.uk/web-focus/papers/mw-2009/>
- Further Developments of a Risks and Opportunities Framework, Kelly, B., UK Web Focus blog, 16 April 2009,
<http://ukwebfocus.wordpress.com/2009/04/16/further-developments-of-a-risks-and-opportunities-framework/>
Filed under: Risk Management | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Introduction
The document An Introduction to the Mobile Web [1] explains how increasing use of mobile devices offers institutions and organisations many opportunities for allowing their resources to be used in exciting new ways. This innovation relates in part to the nature of mobile devices (their portability, location awareness and abundance) but also to the speed and ease with which new applications can be created for them. Some of the current complimentary technologies are described below.
QR Codes
Quick Response (QR) codes are two-dimensional barcodes (matrix codes) that allow their contents to be decoded at high speed. They were created by Japanese corporation Denso-Wave in 1994 and have been primarily used for tracking purposes but have only recently filtered into mainstream use with the creations of applications that allow them to be read by mobile phone cameras. For further information see An Introduction to QR Codes [2].
Location Based Services (GPS)
More mobile phones are now being sold equipped with global Positioning System (GPS) chips. GPS, which uses a global navigation satellite system developed in the US, allows the device to provide pinpoint data about location.
Mobile GPS still has a way to go to become fully accurate when pinpointing locations but the potential of this is clear. GPS enabled devices serve as a very effective navigational aid and maps may eventually become obsolete. Use of GPS offers many opportunities for organisations to market their location effectively.
SMS Short Codes
Instant is already used by consumers in a multitude of ways, for example to vote, enter a competition or answer a quiz. In the future organisations could set up SMS short codes allowing their users to:
- Express an interest in a product or service or request a brochure
- Request a priority call back
- Receive picture, music, or video content
- Receive search results
- Receive a promotional voucher
- Pay for goods or services
- Engage in learning activities
Bluetooth and Bluecasting
Bluetooth is an open wireless protocol for exchanging data over short distances from fixed and mobile devices. Bluecasting is the provision of any media for Bluetooth use. Organisations could offer content to users who opt-in by making their mobile phones discoverable.
Cashless Financial Transactions
Using Paypal it is now possible to send money to anyone with and email address or mobile phone number. Paying using SMS is becoming more common, for example to pay for car parking. In the future people will be able to use the chip in their phone to make contactless payments at the point of sale by waving it across a reader.
The Future
The next ‘big thing’ for mobile devices could be speech recognition. The voice-enabled Web will have significant implications for authentication and ease of use. Future phones are likely to work in a more multi-sensory way and use smell, light and heat more. They may also begin to use artificial intelligence and augmented reality.
References
- An Introduction to the Mobile Web, Cultural Heritage briefing paper no. 62, UKOLN,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-62/>
- An Introduction to QR Codes, Cultural Heritage briefing paper no. 61, UKOLN,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-61/>
Filed under: Mobile Technologies | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
There are No ‘Wrong’ Tags – Are There?
Although from the theoretical viewpoint there are no ‘wrong’ tags, in practice care needs to be taken when creating tags. So here are a few tips.
Tags are Single Words
Each tag takes the form of a single word. This is fine if the idea you want to convey is easily defined as a single word or doesn’t have multiple meanings. If this is not the case, tags can be extended by using a hyphen to link words together and still be treated by software and applications as a single word.
Singular or Plural
There are no rules so you choose whether to use the singular or plural form of a word. However, the choice of ‘museum’ instead of ‘museums’ or ‘library’ instead of ‘libraries’ by either the person tagging or searching will affect the results of the search. Library catalogue subject headings always use the plural form.
Words with Multiple Meanings
Some words can have multiple meanings, which could be confusing. When using the tag ‘violet’ do you mean a flower or a colour or a woman? You might need to extend the tag to make the distinction clear:
violet-flower
violet-colour
violet-UML-editor (a piece of software)
violet-cool-gifts (an Internet shopping site)
violet-hill-song (a song and not a geographical feature)
violet-carson (tv series actress)
violet-posy-blog
Tags for Events and Awards
Web sites that use tags often display the tags visually as a tag cloud. These usually take the form of an alphabetical list of tags and use font size and/or colour to identify the most frequently used tags. This enables viewers to either pick from the alphabetical list or to easily spot the most popular tags.
Tag Cloud Types
If you want to create tags for a series of events or an award, it is advisable to think ahead and devise a consistent set of tags. Start with the name of the event (which might be a well-known acronym) and then extend it using location and/or date.
IFLA-2009 nobel-prize-biology-2000
IFLA-2010 nobel-prize-peace-1999
Note, though, that there are also advantages in having short tags, so sometimes a tag for an event such as IFLA09 may be preferred.
‘Meaningless’ Tags
Within social networking services, people new to tagging often create tags from a very personal viewpoint. These are often effective within a specific context, but of limited use to someone else searching for information.
An advanced Search on Flickr using the tag ‘my-party’ turned up 399 hits. And while extending the tag might be expected to reduce the number of photos found, using ‘ann-party’ actually found 630 hits. Nobody seemed to have extended ‘ann-party’ with a date, but a search on the tag ‘party-2008′ found 901 items.
Even for a personal set of photos, using the tag ‘party’ may well not be enough, if you are a regular party giver or attender. You might need to tag some as ’18th-party’, ‘eurovision-party-2008′, ‘graduation-party’, ‘millennium-party’ or ‘engagement-party’.
Multiple Tags
An advantage of tagging is that any number of tags can be assigned to a resource. Assigning multiple tags to resources may take more time but it does get round some of the problems with tagging. So, if a word could be singular or plural, you could use both terms. Similarly, you could use both formal (or specialist) and informal terms as in ‘oncology’ and ‘cancer’. Multiple tagging also helps when the tagged resource might be searched for via several routes. An image of a dress in a costume collection could be tagged not only with its designer’s name, the year, decade or century it was created, its colour, fabric, length and style features (e.g. sleeveless) but also the occasions when it has been worn and by whom.
A Final Tip
It is worth spending some time considering the above points before deciding on your tags. So think carefully before you tag.
Filed under: Metadata | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
What is a Tag?
Wikipedia defines a tag as “a non-hierarchical keyword or term assigned to a piece of information (such as an internet bookmark, digital image, or computer file)” [1]. Tags, which are a form of metadata, allow resources to be more easier found.
Background
In the pre-Internet era, library catalogues used keywords to help users find titles on specific topics. Later, publishers of early Web sites started to use keywords to help people to find content. Then around 2003, tagging was developed by the social bookmarking site Delicious, and subsequently used by other social software services such as Flickr, YouTube and Technorati.
Tag Features
A list of typical characteristics of tags is given below:
- Tags are chosen by the creator and/or by the viewer of the tagged item.
- Tags are not part of a formal subject indexing term set.
- Tags are informal and personal.
- An item may have multiple tags assigned to it.
- There is no ‘wrong’ tag.
Tag Clouds
Web sites that use tags often display the tags visually as a tag cloud. These usually take the form of an alphabetical list of tags and use font size and/or colour to identify the most frequently used tags. This enables viewers to either pick from the alphabetical list or to easily spot the most popular tags.
Tag Cloud Types
A number of different types of tag clouds may be found. For example:
- The size represents the number of times that tag has been applied to a single item.
- The size represents the number of items to which a specific tag has been applied.
- The size represents the number of items in a content category.
Folksonomies
In situations where many users add tags to lots of items, a collection of tags is built up over time. Such a collection tags may be referred to as a folksonomy. A more formal definition of folksonomy is a set of keywords that is built up collaboratively without a pre-determined hierarchical structure.
Users of tagging systems can see the tags already applied by other people and will often, therefore, choose to use existing tags. However, they will create new tags if no existing tag is suitable or if the existing ones are not specific enough.
Hash Tags (# Tags)
Hash tags (also written as ‘hashtags’) are used in messages using services such as Twitter. The hash symbol (#) is placed before the word to be treated as a tag, as in the example below.
#goji berries are the new #superfood
This enables tweets on a specific topic to be found by searching on the hash tag.
Adding Tags
Systems vary in how you enter tags. When a single text box is provided and you want to enter more than one tag, you will need to use a separator between the tags. The most popular separator is the space character but some systems use other separators; e.g. quotation marks. Other systems only allow one tag to be entered at a time; in these cases you will have to repeat the process to add further tags.
‘Official’ Tags
Events and conferences increasingly are creating ‘official’ tags. These tags can then be used by participants for blog posts, photos of the event, presentation slides and other supporting materials and resources. This use of a consistent tag maximises the effectiveness of searching for resources relating to specific events.
References
- Tag (metadata), Wikipedia,
<http://en.wikipedia.org/wiki/Tag_(metadata)>
Filed under: Metadata | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Introduction
If you have made the decision to create a mobile Web site [1] there are a number of best practice techniques to bear in mind.
URLs
Best practices for URLs for Web sites include:
- Choose a short, easily remembered URL (e.g. xxx.ac.uk/mobile, m.xxx.ac.uk, or xxx.mobi).
- Stick with established conventions.
Navigation
Best practices for navigational design for mobile Web sites include:
- Remember that users are struggling with a variety of “difficult” input devices (stylus, finger touch, control pad, keyboard or joystick) so keep navigation simple.
- Sort navigation elements by popularity – most popular at the top.
- Allow users to see all navigation at once.
- Stick to a maximum of 10 links on any page.
- Code each link as an ‘access key’ numbered 0-9; use 0 for home. This allows users to navigate your links using their phone’s numeric keypad ensuring compatibility with older devices.
- Let people find things with as few clicks as possible – limit your navigation to a max drill-down of 5 levels (users get disorientated by more).
- Use well-labelled navigation categories.
- Provide escape links from every page, either to the next section, to the parent section, to the home page, or all of the above. Note: Breadcrumbing your navigation can be very effective.
- Remember your users don’t have a mouse, so :hover and onClick aren’t helpful.
Markup
Best practices for markup for mobile Web sites include:
- Code in well formed, valid XHMTL-MP (Mobile Profile) See W3C [2].
- Validate all pages. Bad mark-up can easily crash a mobile device, or simply cause nothing to render at all.
- Keep the pages below 30k where possible, so they load reasonably quickly. Bloated pages hurt users.
- Avoid tables, reliance on plug-ins (e.g. Flash), pop-ups, client side redirects and auto-refreshes (which may incur extra download times and data charges).
- Separate content and presentation with CSS. External, inline and embedded CSS are acceptable.
- Avoid @import to reference external CSS files.
- Phone numbers should be selectable links.
- Avoid floats for layout.
Images
Best practices for use of images on mobile Web sites include:
- Aim to keep logos and images small so that they fit within the recommended screen size limitation: 200 pixels wide x 250 pixels height. (Images wider than the screen size limitation should only be used if there is no better way to represent the information).
- When sizing your image to fit the screen resolution, don’t forget about the browser furniture which is going to take up some screen real estate, the scrollbar etc., so your image needs to be slightly smaller.
- Go for bold, high contrast, reduced colour palette images (subtle hues and shading will be lost on the more basic mobiles).
- Use ALT attributes for images as some users may not be able to see images on the Web site (or may choose to disable display of images).
Content
Best practices for the content on mobile Web sites include:
- Make it useful – think about your audience and what they really need, especially when they’re on the go.
- Mobile users have a shorter attention span – provide content in small, snack-sized pieces.
- Provide one content item per page.
- Keep text to the very minimum on each page.
- Use short, direct sentences.
- Minimise scrolling.
- Have a meaningful but short title bar.
- Have your institution’s phone number in the footer of every page.
- Don’t expect people to fill out long forms.
- Lots of video, animation or large image files slow down your site – if you must have them, keep them to a minimum.
- Remember the user’s details. Remembering preferences and behaviour helps you speed up their access to information. Pre-completed forms and “customise my home page” settings are even more critical to mobile than PC sites.
- Label your form fields.
- Use heading styles H1, H2, H3, H4.
- Use minimally sized margins and padding (remember your screen real estate is already small).
Design
Best design practices for mobile Web sites include:
- Switch your thinking to portrait mode where the page is taller than it is wide
- Design to the limitations of the expected screen sizes – 200 pixels wide x 250 pixels height
- Use colour banding for navigation categories, to give a sense of where you are.
‘Sniffing’
It is possible to set up a service to divert all you mobile devices automatically from your desktop site to your mobile site. This process is called ‘sniffing’. You can also sniff to know what mobile handset your user has and display a site optimised to maximum of their capabilities. Both approaches are not recommended.
Testing
Test your site on as many emulators [2] as possible and as many phones as possible. Ask your community to help you test. Make sure your desktop site contains a link to your mobile site and vice versa. The recommended link wordings are: ‘Mobile Site’ and ‘Full Site’. You also need to make sure your mobile site is picked up by all the main search engines (e.g. send Google a mobile sitemap.)
Conclusions
When designing for the mobile Web recognize its limitations (small screen, no mouse) but also think about its extra capabilities (phone, camera, GPS, SMS, MMS, Bluetooth, QR reader, MP3 player etc). Too many mobile websites needlessly limit functionality, offering a bare bones experience that leaves the user wanting more. Mobile devices can do many things – use them in new ways to add real value.
Acknowledgements
This document was written by Sharon Steeples, University of Essex who ran a workshop on this topic at the IWMW 2009 event (see her accompanying handout at [3]). We are grateful to Sharon for permission to republish this document under a Creative Commons licence.
References
- An Introduction to the Mobile Web, Cultural Heritage briefing paper no. 62, UKOLN,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-62/>
- Mobile Web best practices (flip cards), W3C,
<http://www.w3.org/2007/02/mwbp_flip_cards.html>
- The Mobile Web: keep up if you can! Useful links including emulators, Slideshare,
<http://www.slideshare.net/mobilewebslides/supporting-handout-the-mobile-web-keep-up-if-you-can>
Filed under: Mobile Technologies, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
What is the Mobile Web?
Access to Web services used to be only through desk top computers. Improvement of laptop, personal digital assistant (PDA) and mobile phone technologies, alongside expansion of mobile networks, has meant that this is no longer the case. The number of mobile Web users is growing rapidly, now over half the globe pays to use one [1], and any organisation with a Web site will need to give consideration to mobile devices.
Challenges in Exploiting the Mobile Web
For most browsing the Internet using a mobile device is currently not an enjoyable experience [2]. The main challenges relate to interoperability and usability, and stem from the following issues:
- Web technologies may be incompatible with mobile devices – JavaScript, cookies etc. may not work
- There are serious device limitations – smaller screens, difficult to use keyboards, limited battery life etc.
- Mobile network connection can be very slow and intermittent.
At present mobile data connectivity can be costly but this is likely to change. Whatever the challenges, users will increasingly want to access Web sites while on the move.
Opportunities Provided by the Mobile Web
Gaddo F Benedetti, Mobile Web expert, states that “what sells the mobile Web is not how it is similar to the desktop Web, but how it differs” [3]. A mobile device is transportable, personal, always on, prolific and these days often location aware. Such factors offer many opportunities for institutions and organisations who wish to allow their resources to be used in exciting new ways.
Mobile Web Sites
If you are a Web site provider there are a number of options available to you. You could chose to do nothing or merely reduce your images and styling to help with mobile viewing. There are a number of third party sites that will help with this.
Alternately you can create handheld style sheets using CSS or create mobile optimised content using XHTML or WML (wireless markup language) to deliver content. New browsers are moving towards using modifications of HTML. Each approach has its pros and cons which will need consideration.
The Mobi Approach
In July 2005 a number of big companies (Google, Microsoft, Nokia, Samsung, and Vodafone) sponsored the creation of the .mobi top-level domain dedicated to delivering the Internet to mobile devices. Mobi has received criticism because it goes against the principle of device independence.
W3C Mobile Web Initiative
The W3C Mobile Web Initiative [4] is a initiative set up by the W3C to develop best practices and technologies relevant to the Mobile Web. They offer a helpful set of mobile Web best practices and Mobile Web Checker tools. One project WC3 have been involved in is the development of a validation scheme: the Mobile OK scheme.
Creating Mobile Web Sites
If you are creating a mobile Internet site you will need to give some consideration of what information and services your stakeholders will want to consume while on the move, for example opening hours, directions, staff information etc. Currently there are very few dedicated UK cultural heritage mobile sites, however in the US there are more and a number of examples are listed on the Tame the Web blog [5].
References
- Nice talking to you … mobile phone use passes milestone, Guardian, 3 Mar 2009,
<http://www.guardian.co.uk/technology/2009/mar/03/mobile-phones1>
- Mobile Usability, Jakob Nielsen’s Alertbox,
<http://www.useit.com/alertbox/mobile-usability.html>
- Mobile First, Web Second, Mobi Forge blog,
<http://mobiforge.com/analysts/blog/mobile-first-web-second>
- Mobile Web Initiative, W3C,
<http://www.w3.org/Mobile/>
- Mobile Versions of Library Web sites, Tame the Web,
<http://tametheweb.com/2008/06/18/mobile-versions-of-library-web-sites/comment-page-1/>
Filed under: Mobile Technologies, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
What are QR Codes?
Quick Response (QR) codes are two-dimensional barcodes (matrix codes) that allow their contents to be decoded at high speed. They were created by Japanese corporation Denso-Wave in 1994 and have been primarily used for tracking purposes but have only recently filtered into mainstream use with the creations of applications that allow them to be read by mobile phone cameras.
How Can You Read Them?
Users can scan in codes (maybe in a magazine or on a poster) using a mobile phone with a camera or QR reader and QR Code reader software. The decoding software then interprets the code. QR software can be downloaded from the Web: a list of applications suitable for a variety of handsets is available from Tigtags [1]. Users are then provided with a relevant URL, chunk of text, transferred to a phone number or sent an SMS. This act of linking from physical world objects is known as a hardlink or physical world hyperlinks.

Figure 1: QR Code for the UKOLN Cultural Heritage Web site
Creating QR Codes
To create a QR Code you will need to access a QR Code generator then enter the required information. The output is an image file which you can save to your computer. There are a number of freely available QR code generators including Kaywa [2] and i-nigma [3]. An effective QR code should generally be a maximum of 40 – 80 characters (more characters cause the image to degrade), black and white and a minimum of 2cm wide.
Challenges
Currently not all mobile devices have the capacity to include a QR code reader and there are also issues regarding cost and speed of access to networks. QR codes have a limited number of characters and use is currently limited to one action per code.
Potential of QR Codes
QR Codes have great potential within learning and teaching, for example by linking to online resources and allowing user interaction. They are also a great tool for linking information to locations and objects, for example in museums or through the creation of treasure trails. The QR Codes at Bath blog [4] offers many ideas for uses. They can also be used in conjunction with other services (such as a library catalogue) or as a marketing aid by putting onto posters, t-shirts etc. They are very cheap to produce. In December 2008 Pepsi became the first high-profile consumer brand to use QR codes.
QR Codes in the Museum
A blog post on the PowerHouse Museum blog [5] identified a number of opportunities and possible problems in making use of QR code with extended object. The blog post suggested that QR codes are probably best seen just as mobile-readable URLs. However initial experiments with QR codes identified a number of difficulties including not all QR codes are not the same; inconsistent size of QR codes and making the mobile site.
References
- TigTags,
<http://www.tigtags.com/getqr>
- Kayway,
<http://qrcode.kaywa.com/>
- i-nigma,
<http://www.i-nigma.com/i-nigmahp.html>
- QR codes at Bath,
<http://blogs.bath.ac.uk/qrcode/>
- QR codes in the museum – problems and opportunities with extended object, PowerHouse Musuem blog, 5 March 2009,
<http://www.powerhousemuseum.com/dmsblog/index.php/2009/03/05/qr-codes-in-the-museum-problems-and-opportunities-with-extended-object-labels/>
Filed under: Emerging Technologies | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Background
A wide range of standards are available which seek to ensure that networked services are platform and application-independent, accessibility, interoperable and are suitable for re-purposing.
But how does one go about selecting appropriate open standards, especially, as described below, some open standards may fail to reach maturity? This briefing document describes an approach which can support the selection process.
Challenges
Although use of recommended standards and best practices is encouraged, there may be occasions when this is not possible:
- Building on existing systems: Projects may be based on development of existing systems, which do not use appropriate standards.
- Standards immature: Some standards may be new, and there is a lack of experience in their use. Although some organisations may relish the opportunity to be early adopters of new standards, others may prefer to wait until the benefits of the new standards have been established and many teething problems resolved.
- Functionality of the standard: Does the new standard provide functionality which is required for the service to be provided?
- Limited support for standards: There may be limited support for the new standards. For example, there may be a limited range of tools for creating resources based on the new standards or for viewing the resources.
- Limited expertise: There may be limited expertise for developing services based on new standards or there may be limited assistance to call on in case of problems.
- Limited timescales: There may be insufficient time to gain an understanding of new standards and gain experience in use of tools.
In many cases standards will be mature and expertise readily available. The selection of the standards to be deployed can be easily made. What should be done when this isn’t the case?
A Matrix Approach
In light of the challenges which may be faced when wishing to make use of recommended standards and best practices it is suggested that organisations use a matrix approach to resolving these issues.
| Area |
Your Comments |
| Standard |
| How mature is the standard? |
|
| Does the standard provide required functionality? |
|
| Implementation |
| Are authoring tools which support the standard readily available? |
|
| Are viewing tools which support the standard readily available? |
|
| Organisation |
| Is your organisational culture suitable for deployment of the standard? |
|
| Are there strategies in place to continue development in case of staffing changes? |
|
Organisations will need to formulate their own matrix which covers issues relevant to their particular project, funding, organisation, etc.
Implementation
This matrix approach is not intended to provide a definitive solution to the selection of standards. Rather it is intended as a tool which can assist organisations when they go through the process of choosing the standards they intend to use. It is envisaged that development work will document their comments on issues such as those listed above. These comments should inform a discussion within the development team, and possibly with the project’s advisory or steering group. Once a decision has been made the rationale for the decision should be documented. This will help to ensure that the reasonings are still available if members of the development team leave.
For examples of how projects have addressed the selection of standards can see:
Filed under: Standards | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Background
The use of open standards can help provide interoperability and maximise access to online services. However this raises two questions: “Why open standards?” and “What are open standards?”.
Why Open Standards?
Open standards can be useful for a number of reasons:
- Application Independence: To ensure that access to resources is not dependent on a single application.
- Platform Independence: To ensure that access to resources is not restricted to particular hardware platforms.
- Long-term Access: To ensure that quality scholarly resources can be preserved and accessed over a long time frame.
- Accessibility: To ensure that resources can be accessed by people regardless of disabilities.
- Architectural Integrity: To ensure that the architectural framework for the Information Environment is robust and can be developed in the future.
What Are Open Standards?
The term “open standards” is somewhat ambiguous and open to different interpretations. Open standards can mean:
- An open standards-making process.
- Documentation freely available on the Web.
- Use of the standard is uninhibited by licencing or patenting issues.
- Standard ratified by recognised standards body.
- Standards for which there are multiple providers of authoring and viewing tools.
Some examples of recognised open standards bodies are given in Table 1.
Table 1: Examples of Open Standards Organisations
| Standards Body |
Comments |
| W3C |
World Wide Web Consortium (W3C). Responsible for the development of Web standards (known as Recommendations). See <http://www.w3.org/TR/>. Standards include HTML, XML and CSS. |
| IETF |
Internet Engineering Task Force (IETF). Responsible for the development of Internet standards (known as IETF RFCs). See <http://www.ietf.org/rfc.html>. Relevant standards include HTTP, MIME, etc. |
| ISO |
International Organisation For Standardization (ISO). See <http://www.iso.org/iso/en/stdsdevelopment/whowhenhow/how.html>. Relevant standards areas include character sets, networking, etc. |
| NISO |
National Information Standards Organization (NISO). See <http://www.niso.org/>. Relevant standards include Z39.50. |
| IEEE |
Institute of Electrical and Electronics Engineers (IEEE). See <http://www.ieee.org/>. |
| ECMA |
ECMA International. Association responsible for standardisation of Information and Communication Technology Systems (such as JavaScript). See <http://www.ecma-international.org/>. |
Other Types Of Standards
The term proprietary refers to formats which are owned by an organisation, group, etc. Unfortunately since this term has negative connotations, the term industry standard is often used to refer to a widely used proprietary standard e.g., the Microsoft Excel format may be described as an industry standard for spreadsheets.
To further confuse matters, companies which own proprietary formats may choose to make the specification freely available. Alternatively third parties may reverse engineer the specification and publish the specification. In addition tools which can view or create proprietary formats may be available on multiple platforms or as open source.
In these cases, although there may be no obvious barriers to use of the proprietary format, such formats should not be classed as open standards as they have not been approved by a neutral standards body. The organisation owning the format may chose to change the format or the usage conditions at any time.
It should also be noted that proprietary formats may sometimes be standardised by an open standards organisation. This happened during 2009 with the Microsoft Office and Adobe’s PDF formats.
Filed under: Needs-checking, Standards | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Background
Use of video is one of a number of techniques that might be used to amplify an event. The term amplified conference describes a conference or similar event in which the talks and discussions at the conference are ‘amplified’ through use of networked technologies in order to extend the reach of the conference deliberations [01]. In the past video technologies have been available to support events but have normally been expensive to use. Recently the availability of lightweight tools (including mobile devices) have made it much easier to deploy such technologies.
Video Streaming
Filming speakers at an event makes it possible for a speaker to be heard by an audience which isn’t physically present at the conference. Live video streaming has become easier to do and most venues will have some tools in place to allow people off-site to watch events as they happen. This means that remote participants can engage in activity as it takes through the use of other tools such as Twitter [02]. Paying for a dedicated company to stream an event may be one option but there are also cheaper approaches.
Videoing of Talks
If talks cannot be streamed it may still be possible to record them and publish after the event. The availability of conference footage can potentially provide a valuable historical record. The video may also be viewed in significant numbers over time.
Video can also be used in innovative ways such as interviews with participants; promotional clips advertising the event and video clips shown during breaks.
Challenges
When considering use of video at events you will need to address a number of issues:
- Consent
- It is imperative that event organisers seek permission from speakers for the streaming or videoing of their talks. Clarity of intentions will allow resources to be used more effectively after an event possibly, for example through use of a Creative Commons licence [03]. There may be reasons why permission is not granted by some speakers, for example if a speaker wants to speak freely.
- Intrusiveness
- At events where presentations are videoed it may not be just the speaker who is filmed. Delegates may wish to participate in the Q&A session, whether these parts of a presentation are captured or not may require discussion.
- Technologies
- Suitable video equipment may not always be available for use. There may be issues with room layout that prevent you from videoing (such as a lack of power sockets or issues with the line of vision). Occasionally video footage may be created in a difficult to use format.
Addressing the Challenges
Ways of addressing the challenges can include:
- Have a pool of equipment that can be borrowed. Some gadgets such as Flip cameras are cheap and easy to use. Many mobile phones will allow creation of short videos, users will need to bear in mind memory and battery requirements.
- Make sure that those involved in the creation of video are clear on their responsibilities. Discuss matters such as hosting, format and cost in advance.
- Indicate on booking forms what the procedure will be and describe privacy issues in the Acceptable Use Policy (AUP). Some events may require delegates to agree to being photographed (through use of tick boxes on booking forms) whilst others may prefer top inform delegates this may happen.
- Provide a quiet zone in the lecture theatre for participants who wish to avoid being photographed or videoed.
- Have a Creative Commons notice on the lectern so that a rights statement will be embedded in video footage.
- Publicise well. Inform people before an event if you are going to stream it, inform people after an event if you have screen casts/video footage available. Ensure people are aware of tags and the location of resources.
- Take feedback on board. Ask your attendees what they think of use of video at your event and take criticism on board.
References
- Amplified Conference, Wikipedia, <http://en.wikipedia.org/wiki/Amplified_conference>
- Using Twitter at Events, Cultural heritage briefing page no. 56, UKOLN, <http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-56/>
- An Introduction to Creative Commons, Cultural heritage briefing page no. 34, UKOLN, <http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-34/>
Filed under: Technologies at Events | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
History
Copyright is legal device that gives the owner the right to control how a creative work is used. Until several years ago the contents of a database could not be legally protected. Producers of databases that contained factual data could not claim copyright protection which made it impossible for them to prevent others from copying content. On 11 March 1996 the Council of the European Union adopted Directive 96/9/EG giving specific and separate legal rights (and limitations) to databases: database rights.
What is a Database?
A database is defined in the directive as “a collection of independent works, data or other materials which are arranged in a systematic or methodical way and are individually accessible by electronic or other means.” This broad definition could cover anything from mailing lists, repositories, directories and catalogues to telephone directories and encyclopaedias.
A database will be protected by database rights but its individual components (which may be factual data) may not.
What are Database Rights?
There may have been considerable effort in the creation of a database. This effort is known in intellectual property law as the “sweat of the brow (named after the idiom sweat of one’s brow). Database rights specifically protect this effort and investment. Investment includes “any investment, whether of financial, human or technical resources” and substantial means “substantial in terms of quantity or quality or a combination of both”. Metadata will be included in this investment. Infringement of a database right happens if a person extracts or re-utilises all or a substantial part of the contents of a protected database without the consent of the owner. Fair use and use for academic purposes apply to public databases.
Database rights last for fifteen years from the end of the year that the database was made available to the public, or from the end of the year of completion for private databases. Any substantial changes will lead to a new term of database rights.
The biggest database rights case to date was over William Hill Bookmaker’s reuse of the British Horseracing Board’s online database. In 2004 the European Court of Justice ruled that database rights were not infringed.
Other Protection
Databases are treated as a class of literary works and may also be given copyright protection for the selection and/or arrangement of the contents under the terms of the Copyright, Designs and Patents Act 1988. For this to happen the selection and/or arrangement of the contents of the database must be original and require the intellectual creativity of the author. Arrangement of a list of names in alphabetical order would not meet this standard.
If a database, table or compilation does attract copyright protection, this lasts for a period of 70 years from the end of the calendar year in which the author dies. Databases not in the public domain may also be protected under the law of confidence. The Data Protection Act 1998 will also apply to databases containing personal data.
Creating Databases
Those involved in the creation of databases should give consideration to:
- Whether a database qualifies for copyright/database right protection?
- Who is the owner of the database is (i.e. the institution or other)?
- What contracts apply to the creation of the database.
- Offering text/licences that specify how the data may be used.
- Keeping a record of the investment in a database.
Creators should also update databases regularly to ensure that the 15 year protection period recommences.
Further Information
Briefing documents on Introduction To Intellectual Property and Copyright [1] and An Introduction To Creative Commons [2] are also available.
References
- Introduction To Intellectual Property and Copyright, Cultural Heritage briefing document no. 38, UKOLN, <http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-38/>
- An Introduction to Creative Commons, Cultural Heritage briefing document no. 34, UKOLN, <http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-34/>
Filed under: Legal Issues | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
What is Twitter?
As described in [1] Twitter is a micro-blogging service which allows users to send brief posts (known as ‘tweets‘) up to 140 characters long. The tweets are displayed on the users profile page or in a Twitter client by users who have chosen to ‘follow’ the user.
What are Hashtags?
Hashtags [2] are a community-driven convention for adding additional context to your tweets. They are a form of metadata and very similar to tags, as used on social networking sites and blogs. Hashtags are added inline to a post by prefixing a word with a hash symbol: #hashtag. Implementing a hashtag for an event is becoming increasingly popular and allows anyone to comment on event (before, during and after). Users can see all tweets collated through use of a hashtag in a number of ways:
- Using the hashtags site e.g. http://hashtags.org/tag/iwmw2009/
- Running a Twitter search for a term and then following that RSS feed.
- Using a relevant application such as Twemes [3] or Twitterfall [4].
Twitter Use at Events
Twitter can be used at events by:
- Organisers
- By creating a Twitter account an event organisers can offer updates and alert followers to important occurrences in a similar way to an RSS feed. Prior to an event this may take the form of general publicity material. During an event it could be used to alert delegates to problems, for example if a session is cancelled (followers can sign up to have messages delivered directly to their phone). After an event it could be used to alert followers to where resources are held. Organisers of annual events may find it useful to create a generic Twitter account, not a yearly one, which can be used for forthcoming events.
- Delegates
- Those interested in an event can sign up for the event Twitter account to receive relevant information. They can also tweet during the event using the hashtag. This can be a particularly engaging activity if it takes place during presentations and sessions. Discussion about the content of an event (and related) has become known as the Twitter ‘back channel‘.
- Speakers
- By following a Twitter hashtag a presenter could potentially get a better understanding of an audience’s knowledge and the event mood. During a presentation a presenter could answer questions on the fly, use Twitter as a way to ‘ask the crowd’ and as a feedback mechanism.
Benefits
A Twitter back channel has the potential to be embraced by the event organisers and the conference participants alike. It can allow deeper interaction and engagement with content better audience participation. Twitter users tend to get to know each other better so it can enable the establishment of a community alongside more traditional networking activities. Use of Twitter also means that those not physically present can still participate by asking questions and getting a good feeling for the event atmosphere.
Challenges
As Twitter use at events has yet to become mainstream and many will not have appropriate networked devices Twitter may cause a divide in the audience between those using Twitter and those not. Some have argued that event organiser’s involvement should be discouraged and that the back channel should ‘stay a back channel’ and not be brought to the forefront. As with any networked technology some may see its use as disruptive and inappropriate.
Use of a live display (sometime referred to as a ‘Twitterwall’) which provides a live feed of tweets tagged for the event may have dangers. It can allow inappropriate content to surface and may need to be managed. Some events may choose to moderate a back channel display.
Conclusions
As an organiser it can be very exciting to see your event peaking (if your event hashtag is being highly used at that time) and see Twitter well used at your event. However it pays to remember that Twitter is first and foremost a communications mechanism and that the content of Tweets is more valuable than their quantity. Twitter can be an exciting way for you to allow your community to better connect with an event, by listening to what they say and treading carefully you can ensure that everyone benefits.
References
- An Introduction To Twitter, Cultural heritage briefing page no. 36, UKOLN, <http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-36/>
- Hashtags, <http://hashtags.org/>
- Twemes, <http://twemes.com/>
- Twitterfall, <http://www.twitterfall.com/>
Filed under: Needs-checking, Technologies at Events | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Using Networked Applications At Events
Increasingly WiFi networks are available in lecture theatres [1]. With greater ownership of laptops, PDAs, etc. we can expect conference delegates to make use of the networks. There is a danger that this could lead to possible misuse (e.g. accessing inappropriate resources; reading email instead of listening; etc.) This document describes ways in which a proactive approach can be taken in order to exploit enhance learning at events. The information in this document can also be applied to lectures aimed at students.
Design Of PowerPoint Slides
 A simple technique when PowerPoint slides are used is to make the slides available on the Web and embed hypertext links in the slides (as illustrated). This allows delegates to follow links which may be of interest.
A simple technique when PowerPoint slides are used is to make the slides available on the Web and embed hypertext links in the slides (as illustrated). This allows delegates to follow links which may be of interest.
Providing access to PowerPoint slides can also enhance the accessibility of the slides (e.g. visually impaired delegates can zoom in on areas of interest).
Making slides available on Slideshare can also help to maximise access to the slides by allowing the slides to be embedded in Web pages, blogs, etc.
Using Bookmarking Tools
Social bookmarking tools such as del.icio.us can be used to record details of resources mentioned. An illustration of this is shown in the above image in which the ili2006 tag is used to bookmark the resources described in the presentation.
Realtime Discussion Facilities
Providing discussion facilities such as Twitter can enable groups in the lecture theatre to discuss topics of interest [2].
Support For Remote Users
VoIP (Voice over IP) software (such as Skype) and related audio and video-conferencing tools can be used to allow remote speakers to participate in a conference [3] and also to allow delegates to listen to talks without being physically present.
Using Blogs And Wikis
Delegates can make use of blogs to take notes: This is being increasingly used at conferences, especially those with a technical focus, such as IWMW 2006 [4]. Note that blogs are normally used by individuals. In order to allow several blogs related to the same event to be brought together it is advisable to make use of an agreed tag.
Unlike blogs, wikis are normally used in a collaborative way. They may be suitable for use by small groups at a conference (e.g. for not-taking in breakout sessions).
Challenges
Although WiFi networks can provide benefits there are several challenges to be addressed in order to ensure that the technologies do not act as a barrier to learning.
- User Needs
- Although successful at technology-focussed events, the benefits may not apply more widely. There is a need to be appreciative of the event environment and culture. There may also be a need to provide training in use of the technologies.
- AUP
- Consider whether an Acceptable Use Policy (AUP) should be provided.
- Performance Issues, Security, etc.
- There is a need to estimate the bandwidth requirements, etc. in order to ensure that the technical infrastructure can support the demands of the event. There will also be a need to address security issues (e.g. use of firewalls; physical security of laptops, etc.).
- Equal Opportunities
- If not all delegates will possess a networked device, care should be taken to ensure that delegates without such access are not disenfranchised.
References
- Using Networked Technologies To Support Conferences, B. Kelly et al, EUNIS 2005, <http://www.ukoln.ac.uk/web-focus/papers/eunis-2005/paper-1/>
- Using Twitter at Events, Cultural heritage briefing page no. 56, UKOLN, <http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-56/>
- Interacting With Users, Remote In Time And Space, L. Phipps, SOLSTICE 2006, <http://www.ukoln.ac.uk/web-focus/events/conferences/solstice-2006/>
- Workshop Blogs, IWMW 2006, UKOLN, <http://www.ukoln.ac.uk/web-focus/events/workshops/webmaster-2006/blogs/>
Filed under: Technologies at Events | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Using Mobile Telephony Networks
Increasingly WiFi networks are available in lecture theatres, conference venues, etc. We are beginning to see various ways in which networked applications are being used to enhance conferences, workshops and lectures [1].
However there is a need to address issues such as being clear of potential uses, being aware of user requirement and the logistics of providing and supporting use of networked applications.
Availability Of The Network
If you are considering making use of a WiFi network to support an event you will need to ensure that (a) a WiFi network is available; (b) costs, if any, for use of the network and (c) limitations, if any, on use of the network. Note that even if a WiFi network is available, usage may restricted (e.g. to academic users; local users; etc.).
Using Mobile Telephony Networks
You should remember that increasing numbers of users will be able to make use of mobile phone networks at events. This might include users of iPhones and similar smart phones as well as laptop users with 3G data cards.
Demand From The Participants
There may be a danger in being driven by the technology (just because a WiFi network is available does not necessarily mean that the participants will want to make use of it). Different groups may have differing views on the benefits of such technologies (e.g. IT-focussed events or international events attracting participants from North America may be particularly interested in making use of WiFi networks).
If significant demand for use of the WiFi network is expected you may need to discuss this with local network support staff to ensure that (a) the network has sufficient bandwidth to cope with the expected traffic and (b) other networked services have sufficient capacity (e.g. servers handling logins to the network).
Financial And Administrative Issues
If there is a charge for use of the network you will have to decide how this should be paid for? You may choose to let the participants pay for it individually. Alternatively the event organisers may chose to cover the costs.
You will also have to set up a system for managing usernames and passwords for accessing the WiFi network. You may allocate usernames and passwords as participants register or they may have to sign a form before receiving such details.
Support Issues
There will be a need to address the support requirements to ensure that effective use is made of the technologies.
- Participants
- There may be a need to provide training and to ensure participants are aware of how the networked technologies are being used.
- Event Organisers, Speakers, etc.
- Event organisers, chairs or sessions, speakers, etc should also be informed of how the networked technologies may be used and may wish to give comments on whether this is appropriate.
- AUP
- An Acceptable Use Policy (AUP) should be provided which addresses issues such as privacy, copyright, distraction, policies imposed by others, etc.
- Evaluation
- It would be advisable to evaluate use of technologies in order to inform planning for future events.
Acceptable Use Policies
There may be a need to develop an publicise an Acceptable Use Policy (AUP) covering use of networked technologies at events. As an example see [2].
Physical And Security Issues
You will need to address various issues related to the venue and the security of computers. You may need to provide advice on where laptop users should sit (often near a power supply and possibly away from people who do not wish to be distracted by noise). There will also be issues regarding the physical security of computers and the security against viruses, network attacks, etc.
References
- Using Networked Technologies To Support Conferences, Kelly, B. et al, EUNIS, <http://www.ukoln.ac.uk/web-focus/papers/eunis-2005/paper-1/>
- AUP, IWMW 2007, UKOLN, <http://www.ukoln.ac.uk/web-focus/events/workshops/webmaster-2007/aup/>
Filed under: Needs-checking, Technologies at Events | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Introduction
Archiving is a confusing term and can mean the backup of digital resources and/or the long-term preservation of those records. This document talks about the physical archiving of your Web site as the last in a series of steps after selection and appraisal of Web resources has taken place. This will be part of a ‘preservation policy’.
Approaches
Before archiving it is important to consider approaches to preserving your Web site:
- What to do now
- This includes quick-win solutions, actions that can be performed now to get results, or to rescue and protect resources that you have identified as being most at risk. Actions include domain harvesting, remote harvesting, use of the EDRMS, use of the Institutional Repository, and ’2.0 harvesting’. These actions may be attractive because they are quick, and some of them can be performed without involving other people or requiring changes in working. However, they may become expensive to sustain if they do not evolve into strategy.
- Strategic approaches
- This class includes longer-term strategic solutions which take more time to implement, involve some degree of change, and affect more people in the Institution. These include approaches adapted from Lifecycle Management and Records Management and also approaches which involve working with external organisations to do the work (or some of it) for you. The pay-off may be delayed in some cases, but the more these solutions become embedded in the workflow, the more Web-archiving and preservation becomes a matter of course, rather than something which requires reactive responses or constant maintenance, both of which can be resource-hungry methods.
Domain Harvesting
Domain harvesting can be carried out in two ways: 1) Your Institution conducts its own domain harvest, sweeping the entire domain (or domains) using appropriate Web-crawling tools. 2) Your Institution works in partnership with an external agency to do domain harvesting on its behalf. Domain harvesting is only ever a partial solution to the preservation of Web content. Firstly, there are limitations to the systems which currently exist. You may gather too much, including pages and content that you don’t need to preserve. Conversely, you may miss out things which ought to be collected such as: hidden links, secure and encrypted pages, external domains, database-driven content, and databases. Secondly, simply harvesting the material and storing a copy of it may not address all the issues associated with preservation.
Migration
Migration of resources is a form of preservation. Migration is moving resources from one operating system to another, or from one storage system to another. This may raise questions about emulation and performance. Can the resource be successfully extracted from its old system, and behave in an acceptable way in the new system?
Getting Other People to Do it for You
There are a number of third party Web harvesting services which may have a role to play in harvesting your Web site:
- UKWAC
- The UK Web-Archiving Consortium [1] has been gathering and curating Web sites since 2004. To date, UKWAC’s approach has been very selective, and determined by written selection policies which are in some ways quite narrow, it currently only covers UK HE/FE. However it is now possible to nominate your Institutional Web site for capture with UKWAC.
- The Internet Archive
- The Internet Archive [2] is unique in that it has been gathering pages from Web sites since 1996. It holds a lot of Web material that cannot be retrieved or found anywhere else. There are a number of issues to consider when using the Internet Archive. To date it lacks any sort of explicit preservation principle or policy and may not have a sustainable business model and so its use cannot guarantee the preservation of your resources. There are also issues with the technical limitations of the Wayback Machine e.g. gaps between capture dates, broken links, database problems, failure to capture some images, no guarantee to capture to a reliable depth or quality. The National Archives use a model where they contract out collection to the Internet Archive, but also maintain the content themselves.
- HANZO
- Hanzo Archives is a commercial Web-archiving company [3]. They claim to be able to help institutions archive their Web sites and other Web-based resources. They offer a software as a service solution for Web archiving. It’s possible for ownership to be shared at multiple levels; for instance, one can depend on a national infrastructure or service to do the actual preserving, but still place responsibility on the creator or the institution to make use of that national service.
References
- UKWAC, <http://www.webarchive.org.uk/>
- The Internet Archive, <http://www.archive.org/>
- HANZO, <http://www.hanzoarchives.com/>
Filed under: Digital Preservation, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Introduction
This document provides some approaches to selection for preservation of Web resources.
Background
Deciding on a managed set of requirements is absolutely crucial to successful Web preservation. It is possible that, faced with the enormity of the task, many organisations decide that any sort of capture and preservation action is impossible and it is safer to do nothing.
It is worth remembering, however, that a preservation strategy won’t necessarily mean preserving every single version of every single resource and may not always mean “keeping forever”, as permanent preservation is not the only viable option. Your preservation actions don’t have to result in a “perfect” solution but once decided upon you must manage resources in order to preserve them. An unmanaged resource is difficult, if not impossible, to preserve.
The task can be made more manageable by careful appraisal of the Web resources, a process that will result in selection of certain resources for inclusion in the scope of the programme. Appraisal decisions will be informed by understanding the usage currently made of organisational Web sites and other Web-based services and the nature of the digital content which appears on these services.
Considerations
Some questions that will need consideration include:
- Should the entire Web site be archived or just selected pages from the Web site?
- Could inclusion be managed on a departmental basis, prioritising some departmental pages while excluding others?
You will also be looking for unique, valuable and unprotected resources, such as:
- Resources which only exist in web-based format.
- Resources which do not exist anywhere else but on the Web site.
- Resources whose ownership or responsibility is unclear, or lacking altogether.
- Resources that constitute records, according to definitions supplied by the records manager.
- Resources that have potential archival value, according to definitions supplied by the archivists.
Resources to be Preserved
(1) RECORD
A traditional description of a ‘record’ is:
“Recorded information, in any form, created or received and maintained by an organisation or person in the transaction of business or conduct of affairs and kept as evidence of such activity.”
A Web resource is a record if it:
- Constitutes evidence of business activity that you need to refer to again.
- Is evidence of a transaction.
- Is needed to be kept for legal reasons.
(2) PUBLICATION
A traditional description of a publication is:
“A work is deemed to have been published if reproductions of the work or edition have been made available (whether by sale or otherwise) to the public.”
A Web resource is a publication if it is:
- A Web page that’s exposed to the public on the Web site.
- An attachment to a Web page (e.g. a PDF or MS Word Document) that’s exposed on the Web site.
- A copy of a digital resource, e.g. a report or dissertation, that has already been published by other means.
(3) ARTEFACT
A Web resource is an artefact if it:
- Has intrinsic value to the organisation for historical or heritage purposes.
- Is an example of a significant milestone in the organisation’s technical progress, for example the first instance of using a particular type of software.
Resources to be Excluded
There are some resources that can be excluded such as resources that are already being managed elsewhere e.g. asset collections, databases, electronic journals, repositories, etc. You can also exclude duplicate copies and resources that have no value.
Selection Steps
Selection of Web resources for preservation requires two steps:
- Devise a selection policy- defining a selection policy in line with your organisational preservation requirements. The policy could be placed within the context of high-level organisational policies, and aligned with any relevant or analogous existing policies.
- Build a collection list.
Selection Approaches
Approaches to selection include:
- Unselective approach
- This involves collecting everything possible. This approach can create large amounts of unsorted and potentially useless data, and commit additional resources to its storage.
- Thematic selection
- A ‘semi-selective’ approach. Selection could be based on predetermined themes, so long as the themes are agreed as relevant and useful and will assist in the furtherance of preserving the correct resources.
- Selective approach
- This is the most narrowly-defined method which does tend to define implicit or explicit assumptions about the material that will not be selected and therefore not preserved. The JISC PoWR project recommend this approach [1].
Resource Questions
Questions about the resources which should be answered include:
- Is the resource needed by staff to perform a specific task?
- Has the resource been accessed in the last six months?
- Is the resource the only known copy, or the only way to access the content?
- Is the resource part of the organisation’s Web publication scheme?
- Can the resource be re-used or repurposed?
- Is the resource required for audit purposes?
- Are there legal reasons for keeping the resource?
- Does the resource represent a significant financial investment in terms of staff cost and time spent creating it?
- Does it have potential heritage or historical value?
An example selection policy is available from the National Library of Australia [2].
Decision Tree
Another potentially useful tool is the Decision Tree [3] produced by the Digital Preservation Coalition. It is intended to help you build a selection policy for digital resources, although we should point out that it was intended for use in a digital archive or repository. The Decision Tree may have some value for appraising Web resources if it is suitably adapted.
Aspects to be Captured
It is possible to make a distinction between preserving an experience and preserving the information which the experience makes available.
Information = content (which could be words, images, audio, …) Experience = the experience of accessing that content on the Web, which all its attendant behaviours and aspects
Making this decision should be driven by the question “Why would we want to preserve what’s on the Web?” When deciding upon the answer it might be useful to bear in mind drivers such as evidence and record-keeping, repurposing and reuse and social history.
References
- JISC PoWR, <http://jiscpowr.jiscinvolve.org/>
- Selection Guidelines for Archiving and Preservation by the National Library of Australia, National Library of Australia, <http://pandora.nla.gov.au/selectionguidelines.html>
- Digital Preservation Coalition Decision Tree, Digital Preservation Coalition, <http://www.dpconline.org/graphics/handbook/dec-tree-select.html>
Filed under: Digital Preservation, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Introduction
An organisation’s home page provides the doorway to its Web site. How it changes over time reflects both how an organisation has changed and how the Web has changed. Keeping a record of both the visual and structural changes of the home page could be very important in the future.
Scenario
Suppose your organisation is about to commemorate an important anniversary (10 years, 50 years or 250 years since it was founded). Your director wants to highlight the fact that the organisations is actively engaging with new technologies and would like to provide an example of how the organisation’s Web site has developed since it was launched. The challenge:
How has your organisational home page changed over time? Have you kept records of the changes and the decisions which were made? If the above scenario took place in your organisations, do you feel you would be able to deliver a solution?
Although most Web managers will be aware of the most significant changes (such as a CMS brought in, search added, changes in navigation, branding, accessibility, language, content, interactive elements and multimedia) currently there is likely to only be anecdotal evidence and tacit knowledge.
Internet Archive
One option may be to use the Internet Archive (IA) [1] to view the recorded occurrences of the organisation’s home page. The IA is a non-profit organisation founded to build an Internet library, with the purpose of offering access to historical collections that exist in digital format. There are a number of issues to consider when using the IA e.g. it lacks explicit preservation principles and may not have a sustainable business model and so its use cannot guarantee the preservation of your resources.
Example: As part of the JISC PoWR project an interactive display was created of the University of Bath’s home page using IA screenshots [2]. In addition to this display a brief video with accompanying commentary was also created, which discusses some of the changes to the home page over the 11 years.
Compiled History
Building a compiled history is another approach. A 14 year’s history of the University of Virginia’s Web site from 1994-2008 [3] is available from their site. They provide details of the Web usage statistics in the early years, with screen images shown of major changes to the home page from 1997. There is also a time line and access to archived sites from 1996 onwards.
Preserving for the Future
The best way that you can ensure that your organisation’s home page is preserved is ensuring that it gets documented in a preservation policy or as part of a retention schedule. Once this has been agreed there are a number of available options.
- Domain harvesting of the site:
- Your home page could be captured as part of a harvesting programme. Your organisation could conduct its own domain harvest, sweeping the entire domain (or domains) using appropriate Web-crawling tools or work in partnership with an external agency to do domain harvesting on its behalf.
- UKWAC:
- The UK Web-Archiving Consortium (UKWAC) [4] has been gathering and curating Web sites since 2004. To date, UKWAC’s approach has been selective: although you can now nominate Web sites for capture with UKWAC.
- Adobe Capture:
- There is a built-in part of Adobe Acrobat which allows Web sites to be captured to a PDF file.
- Exploration of your Content Management System options:
- There may be some scope for preservation using your CMS.
Conclusions
Responsibility for the preservation of your organisation’s Web site may fall in many places but will ultimately require shared ownership. Although there may be ways to easily access snap shots of your home page, if you would like long-term access you will need to embark upon some sort of preservation strategy.
References
- Internet Archive, <http://www.archive.org/>
- Visualisation of University of Bath Home page changes, UKOLN, <http://www.ukoln.ac.uk/web-focus/experiments/experiment-20080612/>
- History of UVA on the Web, <http://www.virginia.edu/virginia/archive/>
- UWAC, <http://www.webarchive.org.uk/>
Filed under: Digital Preservation | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Introduction
We have become increasingly familiar with the term Web 2.0, referring in a very general way to the recent explosion of highly interactive and personalised Web services and applications. Collaboration and social networking are a key feature, for example through contributing comments or sharing write access and collaborating. Many of these applications have now crossed the threshold between private, personal use and applications used at work.
Web 2.0 Applications
In a briefing paper for JISC, Mark van Harmelen defined seven types of Web 2.0 applications [1]: blogs, wikis, social bookmarking, media sharing services, social networking systems, collaborative editing tools and syndication and notification technologies.
Some of these applications and services listed above are still at an ‘experimental’ stage and (at time of writing) being used in organisations primarily by early adopters of new technologies. But it is possible to discern the same underlying issues with all these applications, regardless of the software or its outputs.
Web 2.0 Issues
Preservation of Web 2.0 resources presents a number of different challenges to preservation of standard Web resources. These include:
- Use of third party services: data may be held on a provider’s server.
- More complex ownership, IPR and authentication issues.
- Data held may be personal and difficult to extract.
- Emphasis on collaboration and communication rather than access to resources.
- Richer diversity of services.
- Is the data worth preserving at all?
Ownership and Responsibility
Quite often these applications rely on the individual to create and manage their own resources. A likely scenario is that the user creates and manages his or her own external accounts in Flickr, Slideshare or WordPress.com; but they are not organisational accounts. By contrast, one would expect blogs and wikis hosted by the organisation to offer more commitment to maintenance, in line with existing policies on rights, retention and reuse, as expressed in IT and information policy, conditions of employment, etc.
Third-party sites such as Slideshare or YouTube are excellent for dissemination, but they cannot be relied on to preserve your materials permanently. If you have created a resource – slideshow, moving image, audio, whatever it be – that requires retention or preservation, then someone needs to make arrangements for the ‘master copy’. Ideally, you want to bring these arrangements in line with the larger Web archiving programme. However, if there is a need for short-term action, and the amount of resources involved are (though important) relatively small, then remedial action for master copies may be appropriate. Some possible remedial actions are:
- Store it in the Electronic Document Records Management System
- Store it on the Institution Web site
- Store it in the Institutional Repository
- Store it on a local networked drive
In the case of blogs, wikis and collaborative tools, content is created directly in them, and access is normally dependent on the availability of the host and the continued functioning of the software. Users of such tools should be encouraged and assisted to ensure significant outputs of online collaborative work are exported and managed locally.
Conclusion
It is unclear at this stage if Web 2.0 offers a new set of challenges or an enhancement of existing ones. The really challenging problems are organisational e.g. how can an organisation identify “its content” on something like Slideshare? Who ultimately “owns” content? How (and should) things be “unpublished”? A number of case studies of preservation of Web 2.0 resources are available from the JISC PoWR Web site [2].
References
- An Introduction to Web 2.0, Cultural Heritage briefing paper no. 1, UKOLN, <http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-1/>
- JISC PoWR Web 2.0, JISC PoWR Blog, <http://jiscpowr.jiscinvolve.org/category/Web-20/>
Filed under: Digital Preservation | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Introduction
Institutions now create huge amounts of Web-based resources and the strategic importance of these is finally being recognised. Long-term stewardship of these resources by their owners is increasingly becoming a topic of interest and necessity.
What is Web ‘Preservation’?
Digital preservation is defined as a “series of managed activities necessary to ensure continued access to digital materials for as long as necessary” [1]. In the case of Web resources you may choose to go for:
- Protection: Protecting a resource from loss or damage, in the short term, is an acceptable form of “preservation”, even if you don’t intend to keep it for longer than, say, five years.
- Perpetual preservation It is best to think of this as long-term preservation where ‘long-term is defined as “long enough to be concerned with the impacts of changing technologies, including support for new media and data formats, or with a changing user community” [2].
Why Preserve?
There are a number of drivers for Web resource preservation:
- To protect your organisation: Web sites may contain evidence of organisational activity which is not recorded elsewhere and may be lost if the Web site is not archived or regular snapshots are not taken. There are legal requirements to comply with acts such as FOI and DPA.
- It could save you money: Web resources cost money to create, and to store; failing to repurpose and reuse them will be a waste of money.
- Responsibility to users: Organisations have a responsibility to the people who use their resource and to the people who may need to use their resources in the future. People may make serious choices based on Web site information and there is a responsibility to keep a record of the publication programme. Many resources are unique and deleting them may mean that invaluable scholarly, cultural and scientific resources (heritage records) will be unavailable to future generations.
Whose Responsibility is it?
There are a number of parties who may have an interest in the preservation of Web resources. These may include the producer of the resource (Individual level), the publisher of the resource, the organisation, the library (Organisational Level), the cultural heritage sector, libraries and archives, the government, consortiums (National Level) or international organisations, commercial companies (International level). Within organisations the Web team, records management team, archives and information managers will all need to work together.
What Resources?
The JISC Preservation of Web Resources (PoWR) project [3] recommends a selective approach (as oppose to full domain harvesting). This won’t necessarily mean preserving every single version of every single resource and may not always mean “keeping forever”, as permanent preservation is not the only viable option. Your preservation actions don’t have to result in a “perfect” solution but once decided upon you must manage resources in order to preserve them. An unmanaged resource is difficult, if not impossible, to preserve. Periodic snapshots of a Web site can also be useful and could sit alongside a managed solution.
How Do I Preserve Web Resources?
Web preservation needs to be policy-driven. It is about changing behaviour and consistently working to policies. As a start an organisation might go about creating a Web resource preservation strategy. Some of the following questions will be worth considering: What Web resources have you got? Where are they? Why have you got them? Who wants them? For how long? What protection policies do you have?
Ways of finding out the answers to these questions include a survey, research, asking your DNS manager. Once you have found your resources you need to appraise them and select which require preserving. The next step is to move copies of your resources into archival storage. Once this process is completed the resources will need to be managed in some way. For further information see the Web Archiving briefing paper [4].
References
- Digital Preservation Coalition Definitions, Digital Preservation Coalition, <http://www.dpconline.org/graphics/intro/definitions.html>
- Digital preservation, Wikipedia, <http://en.wikipedia.org/wiki/Digital_preservation#cite_note-1>
- JISC PoWR blog site, <http://jiscpowr.jiscinvolve.org/>
- Web Archiving, Cultural heritage briefing paper no. 53, UKOLN, <http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-53/>
Filed under: Digital Preservation, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
What Is A Wiki?
A wiki is a Web site that uses wiki software, allowing the easy creation and editing of any number of interlinked Web pages, using a simplified markup language or a WYSIWYG text editor, within the browser [1].
The key characteristics of typical wikis are:
- The ability to create and edit content within a Web environment without the need to download any special software.
- Use of a simple markup language which is designed to simplify the process of creating and editing documents.
- The ability to easily create and edit content, often without need for special privileges.
Wikipedia – The Best Known Wiki
 Wikipedia is probably the largest and best-known example of a wiki – see <http://www.wikipedia.org/>.
Wikipedia is probably the largest and best-known example of a wiki – see <http://www.wikipedia.org/>.
Wikipedia is a good example of a wiki in which content is provided by contributors around the world.
Wikipedia appears to have succeeded in providing an environment and culture which has minimised the dangers of misuse. Details of the approaches taken on Wikipedia are given on the Wikimedia Web site [2].
What Can Wikis Be Used For?
Wikis can be used for a number of purposes:
- On public Web sites to enable end users to easily contribute information, such as the Science Museums Object Wiki [3].
- Wikis can support communities of practice. For example see the Museums Wiki site [4], the Blogging Libraries Wiki [5] and the AHA’s Archives Wiki [6].
- Wikis can be used to allow local residents to contribute to an official archive [7].
Wikis – The Pros And Cons
As described in [8] advantages of wikis may include (a) there is no need to install HTML authoring tools; (b) minimal training may be needed; (c) it can help develop a culture of sharing and working together (cf. open source); (d) it can be useful for joint working when there are agreed shared goals.
However, as described in [9] take-up of wikis in the public sector has been low in the public sector for various reasons: (a) the success of the Wikipedia may not necessarily be replicated elsewhere; (b) concerns that inappropriate content made be added to a wiki; (c) a collaborative wiki may suffer from a lack of a strong vision or leadership; (d) it can be ineffective when there is a lack of consensus; (e) it may be difficult for wikis to gain momentum; (f) there may be copyright and other legal issues regarding collaborative content and (g) there is not a standard wiki markup language. More recently Looseley and Roberto [10] have suggested ways of overcoming such barriers.
References
- Wiki, Wikipedia, <http://en.wikipedia.org/wiki/Wiki>
- Wikimedia principles, Wikimedia, <http://meta.wikimedia.org/wiki/Wikimedia_principles>
- Museums wiki, Wikia, <http://museums.wikia.com/>
- Science Museum Object Wiki, Science Museum, <http://objectwiki.sciencemuseum.org.uk/>
- Blogging Libraries Wiki, <http://www.blogwithoutalibrary.net/links/>
- AHA’s Archives Wiki, <http://archiveswiki.historians.org/>
- War Memorial Wiki, London Borough of Lewisham, <http://lewishamwarmemorials.wikidot.com/>
- Making the Case for a Wiki, E. Tonkin, Ariadne 42, Jan. 2005, <http://www.ariadne.ac.uk/issue42/tonkin/>
- Wiki or Won’t He? A Tale of Public Sector Wikis, M. Guy, Ariadne 49, Oct. 2006, <http://www.ariadne.ac.uk/issue49/guy/>
- Museums & Wikis: Two Case Studies, R. Looseley and F. Roberto, MW 2009, <http://www.archimuse.com/mw2009/abstracts/prg_335001924.html>
Filed under: Web 2.0 | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
What is Cloud Computing?
Cloud computing is an umbrella term used to refer to Internet based development and services. The cloud is a metaphor for the Internet. A number of characteristics define cloud data, applications services and infrastructure:
- Remotely hosted: Services or data are hosted on someone else’s infrastructure.
- Ubiquitous: Services or data are available from anywhere.
- Commodified: The result is a utility computing model similar to traditional that of traditional utilities, like gas and electricity. You pay for what you would like.
Software as a Service (SaaS)
SaaS is a model of software deployment where an application is hosted as a service provided to customers across the Internet. SaaS is generally used to refer to business software rather than consumer software, which falls under Web 2.0. By removing the need to install and run an application on a user’s own computer it is seen as a way for businesses to get the same benefits as commercial software with smaller cost outlay. Saas also alleviates the burden of software maintenance and support but users relinquish control over software versions and requirements. They other terms that are used in this sphere include Platform as a Service (PaaS) and Infrastructure as a Service (IaaS)
Cloud Storage
Several large Web companies (such as Amazon and Google) are now exploiting the fact that they have data storage capacity which can be hired out to others. This approach, known as ‘cloud storage’ allows data stored remotely to be temporarily cached on desktop computers, mobile phones or other Internet-linked devices. Amazon’s Elastic Compute Cloud (EC2) and Simple Storage Solution (S3) are well known examples.
Data Cloud
Cloud Services can also be used to hold structured data. There has been some discussion of this being a potentially useful notion possibly aligned with the Semantic Web [2], though concerns, such as this resulting in data becoming undifferentiated [3], have been raised.
Opportunities and Challenges
The use of the cloud provides a number of opportunities:
- It enables services to be used without any understanding of their infrastructure.
- Cloud computing works using economies of scale. It lowers the outlay expense for start up companies, as they would no longer need to buy their own software or servers. Cost would be by on-demand pricing. Vendors and Service providers claim costs by establishing an ongoing revenue stream.
- Data and services are stored remotely but accessible from ‘anywhere’.
In parallel there has been backlash against cloud computing:
- Use of cloud computing means dependence on others and that could possibly limit flexibility and innovation. The ‘others’ are likely become the bigger Internet companies like Google and IBM who may monopolise the market. Some argue that this use of supercomputers is a return to the time of mainframe computing that the PC was a reaction against.
- Security could prove to be a big issue. It is still unclear how safe outsourced data is and when using these services ownership of data is not always clear.
- There are also issues relating to policy and access. If your data is stored abroad whose FOI policy do you adhere to? What happens if the remote server goes down? How will you then access files? There have been cases of users being locked out of accounts and losing access to data.
The Future
Many of the activities loosely grouped together under cloud computing have already been happening and centralised computing activity is not a new phenomena: Grid Computing was the last research-led centralised approach. However there are concerns that the mainstream adoption of cloud computing could cause many problems for users. Whether these worries are grounded or not has yet to be seen.
References
- Software as a service, Wikipedia, <http://en.wikipedia.org/wiki/Software_as_a_service>
- Welcome to the Data Cloud, The Semantic Web blog, 6 Oct 2008, <http://blogs.zdnet.com/semantic-web/?p=205>
- Any any any old data, Paul Walk’s blog, 7 Oct 2008, <http://blog.paulwalk.net/2008/10/07/any-any-any-old-data/>
Filed under: Needs-checking, Web Technologies | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
What is a Web API?
API stands for ‘application programming interface’. An API is the interface that a computer system, computer library or application provides to allow requests for services to be made of it by other programs and/or to allow data to be exchanged between them. A Web API is the Web version of this interface [1]. It comprises of documented code and is effectively a way to plug one Web site or Web service into another.
Recently many Web sites have exposed APIs and made them available to external developers. The term Open API is often used to describe the technologies that allow this interaction.
What Can Web APIs be Used For?
Developers can use Web APIs to build tools for the host Web site and enrich their own applications with useful functions from third parties. This provides several advantages:
- For the host site:
- The advantage of exposing ones APIs is that developers will create new features and applications for free. These applications will then drive traffic to the site.
- For the developer:
- Creating applications allows developers to promote their own work on higher profile Web site and build on existing work. Their own Web site can then benefit from the traffic. Developers can also mix and match information data from different sources to creation a solution to a problem.
Getting Started
To access a Web API developers will normally need to register for a (often free) account and get a private key which is required for calling server functions. Each API has its own terms and conditions that will need to be followed, for example there may be limitations on the number of calls to the site per day.
Someone with programming experience could build an application using available APIs fairly quickly but there are now a number of good development tools available such as Yahoo Pipes [2] that allow those with little programming experience to begin developing simple Web applications.
Examples of Web APIs
Many commercial companies now expose their APIs including Facebook, Yahoo, Google, Google Maps, Flickr and YouTube.
There are a number of API directories including Programmable Web API directory [3], Webmashup [4] and the WebAPI Directory [5]. A list of useful APIs for library services on the TechEssense.info blog [6].
Opportunities and Challenges
Web APIs are likely to become increasingly important and more organisations will want to make their own APIs available as a way to raise their profile and add value. Amazon recently released graphs that show the growth in bandwidth being consumed by their customers via their various Web services. More activity network activity takes place in this way than through all their other Web sites combined. Uptake of data and software by third party Web applications through Machine to Machine (M2M) interfaces is becoming more important than user interfaces.
This move of focus means that more work will be done to make sure that APIs that deigned in an appropriate and compatible manner. There will also be significant challenges relating to how organisations use the data available, which may be personal and sensitive.
References
- Wikipedia: API, Wikipedia, <http://en.wikipedia.org/wiki/Application_programming_interface>
- Yahoo Pipes, Yahoo!, <http://pipes.yahoo.com/pipes/>
- Programmable Web API directory, <http://www.programmableweb.com/apilist>
- Webmashup, Webmashup.com, <http://www.webmashup.com/Mashup_APIs/>
- WebAPI Directory, WebAPI.org, <http://www.webapi.org/webapi-directory/>
- Services/APIs/Systems/Technology/Data that we could use, Mashed Library, Ning.com, <http://mashedlibrary.ning.com/forum/topic/show?id=2186716%3ATopic%3A9>
Filed under: APIs, Needs-checking | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
What Is OPML?
OPML is defined in Wikipedia as “an XML format for outlines” [1]. OPML stands for Outline Processor Markup Language. It was originally developed as an outlining application by Radio Userland. However it has been adopted for a range of other applications, in particular providing an exchange format for RSS.
Why The Interest?
Grouping Feeds
As an example of the user benefits which OPML can provide let us look at the various RSS feeds which are available on the BBC Web site. These include RSS feeds for:
- News items
- Sports
- TV programmes
- Regional items
- Podcasts
- …
In each of these areas there might be multiple additional feeds. For example the Sports feed could provide general news covering all sports, with additional categories for individual sports. Then might then be news feeds for individuals sports teams.
OPML provides a mechanism for grouping related RSS feeds, allowing them to be processed collectively rather than individually. This can be particularly useful if you wish to subscribe to a group of feeds. An example of how the BBC make use of OPML files for their podcasts can be seen at [2].
Export and Import of Feeds
OPML can also be used if you wish to migrate your feeds from one RSS reader/aggregator to another.
Examples
User Interface to Resources
Use of the Grazr widget on the UKOLN Cultural Heritage Web site [3] is illustrated.
In this example RSS feeds have been created for all the briefing documents, new briefing documents and other lists of resources. These RSS feeds are described in an OPML file. The Grazr widget then allows these files to be navigated and once a suitable resource has been found it can be opened in the Web browser window.
Netvibes and Google Reader
As illustrated, RSS readers such as Reedreader allow RSS files to be imported and exported as OPML files.
This can be useful if you wish to migrate large numbers of RSS feeds from one RSS reader to another.
This may also be useful if you wish to share your list of RSS feeds with other users.
An example of a similar interface in the Google Reader is also illustrated.
The ability to easily migrate data between applications not only provides greater flexibility for the user, it also minimises risks of data being trapped into a particular application.
References
- OPML, Wikipedia,
<http://en.wikipedia.org/wiki/OPML>
- OPML feed of podcasts, BBC,
<http://www.bbc.co.uk/blogs/radiolabs/2008/04/opml_feed_of_podcasts.shtml>
- RSS Feeds, Cultural Heritage, UKOLN,
<http://www.ukoln.ac.uk/cultural-heritage/rss/>
Filed under: Syndication Technologies | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
About RSS and Atom
RSS is defined in Wikipedia as “a family of Web feed formats used to publish frequently updated works – such as blog entries, news headlines, audio and video – in a standardized format” [1]. RSS and the related Atom standard can be used to provide alerts and syndication of content. These lightweight standards play an important role in a Web 2.0 environment in allowing content to be easily reused.
How RSS and Atom Are Being Used
News feeds are an example of automated syndication. News feed technologies allow information to be automatically provided and updated on Web sites, emailed to users, etc. As the name implies news feeds are normally used to provide news; however the technology can be used to syndicate a wide range of information.
Examples of use of RSS on organisational Web sites include:
- The Forestry Commission Scotland which provides RSS feeds for news and information on trail conditions [2]
- The Old Operating Theatre and Herb Garret which provides RSS feeds for information on news, events, grants received and development plans [3]
- The Kids and Reading service which provides RSS feeds on latest articles and news [4]
RSS and Atom are widely used by popular Web 2.0 services, allowing the content provided by the services to be viewed without the user having to visit the service. Examples include:
- Amazon which provides RSS feeds on the availability of new products [5]
- Flickr which provides a variety of customisable RSS feeds [6]
- YouTube which provides a variety of RSS feeds about various categorised groups of videos[7]
- The BBC which provides a large numbers of RSS feeds covering the range of its services [8]
RSS Feeds Readers
As described in [9] there are a large number of RSS reader / RSS aggregation tools available. Examples of different types of RSS readers are summarised below.
- Google Reader: Google Reader [10] is an example of a popular Web-based RSS reader.
- Newsgator and NetNewsWire: Netnewswire [11] is an RSS client for the iPhone/iPod Touch mobile devices which is integrated with the Newsgator Web-based RSS client.
- Netvibes and PageFlakes: Netvibes [12] and PageFlakes [13] are Web-based RSS readers which provide a more graphical style of interface than Google Reader.
- Feedreader Feedreader [14] is an RSS reader for the desktop.
- Outlook 2007 Email Client The Microsoft Outlook 2007 email client [15] includes an RSS reader. This will enable you to read RSS feeds in a similar fashion to reading email.
References
- RSS, Wikipedia,
<http://en.wikipedia.org/wiki/RSS>
- Forestry Commission Scotland,
<http://www.7stanes.gov.uk/forestry/INFD-6ZGJZM>
- The Old Operating Theatre and Herb Garret,
<http://www.thegarret.org.uk/rssfeed.htm>
- Kids and Reading Service,
<http://www.kidsandreading.co.uk/>
- Product RSS Feeds, Amazon,
<http://www.amazon.com/Product-RSS-Feeds/b?node=390052011>
- Flickr Services, Flickr,
<http://www.flickr.com/services/feeds/>
- About RSS, YouTube,
<http://www.youtube.com/rssls>
- News Feeds From The BBC, BBC,
<http://news.bbc.co.uk/1/hi/help/3223484.stm>
- Aggregator, Wikipedia,
<http://en.wikipedia.org/wiki/Aggregator>
- Google Reader, Google,
<http://www.google.com/reader/view/>
- Online News Reader, Newsgator,
<http://www.newsgator.com/individuals/>
- Netvibes,
<http://www.netvibes.com/>
- Pageflakes,
<http://www.pageflakes.com/>
- Feedreader,
<http://www.feedreader.com/features.php>
- Get Your RSS Feeds For Outlook, Microsoft,
<http://office.microsoft.com/en-us/help/HA102148541033.aspx>
Filed under: Syndication Technologies | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
What Is AJAX?
AJAX (Asynchronous JavaScript and XML) is “a group of interrelated Web development techniques used to create interactive web applications or rich Internet applications” [1]. Using AJAX it is possible to develop Web applications which have a rich user interface which can approach the usability of well-written desktop application.
The Origins of AJAX
The key technical components of AJAX are:
- XHTML – a stricter, cleaner rendering of HTML into XML.
- CSS for marking up and adding styles.
- The Javascript Document Object Model (DOM) which allows the content, structure and style of a document to be dynamically accessed and updated.
- ” The XMLHttpRequest object which exchanges data asynchronously with the Web server reducing the need to continually fetch resources from the server.
Since data can be sent and retrieved without requiring the user to reload an entire Web page, small amounts of data can be transferred as and when required. Moreover, page elements can be dynamically refreshed at any level of granularity to reflect this. An AJAX application performs in a similar way to local applications residing on a user’s machine, resulting in a user experience that may differ from traditional Web browsing.
Examples of AJAX usage include GMail and Flickr. It is largely due to these and other prominent sites that AJAX has become popular only relatively recently – the technology has been available for some time. One precursor was dynamic HTML (DHTML), which twinned HTML with CSS and JavaScript but suffered from cross-browser compatibility issues.
AJAX is not a technology, rather, the term refers to a proposed set of methods using a number of existing technologies. As yet, there is no firm AJAX standard, although the recent establishment of the Open AJAX Alliance [2], supported by major industry figures such as IBM and Google, suggests that one will become available soon.
Developing AJAX Applications
AJAX applications can benefit both the user and the developer. Web applications can respond much more quickly to many types of user interaction and avoid repeatedly sending unchanged information across the network. Also, because AJAX technologies are open, they are supported in all JavaScript-enabled browsers, regardless of operating system – however, implementation differences between browsers cause some issues, some using an ActiveX object, others providing a native implementation.
Although the techniques within AJAX are relatively mature, the overall approach is still fairly new and there has been criticism of the usability of its applications; further information on this subject is available in the AJAX And Usability Issues briefing document [2].
Advantages and Disadvantages of AJAX
As described in Wikipedia advantages provided by use of AJAX include:
- State can be maintained throughout a Web site.
- A Web application can request only the content that needs to be updated, thus drastically reducing bandwidth usage and load time.
- Users may perceive an AJAX-enabled application to be faster or more responsive.
- Use of Ajax can reduce connections to the server, since scripts and style sheets only have to be requested once.
The disadvantages include:
- Clicking the browser’s “back” button may not function as expected.
- Dynamic Web page updates make it difficult for a user to use bookmarks.
- Browser does not support JavaScript or have JavaScript disabled, will not be able to use its functionality.
References
- AJAX (programming), Wikipedia,
<http://en.wikipedia.org/wiki/Ajax_(programming)>
- The Open AJAX Alliance,
<http://www.openajax.org/overview.php>
- AJAX And Usability Issues, Cultural Heritage briefing document no. 20, UKOLN,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-20/>
Filed under: Needs-checking, Web Technologies | No Comments »
Posted on September 2nd, 2010 by Brian Kelly
Why Do I Need a Preservation Policy?
The digital world is one of continual change and rapid development of technology. Web sites change content, are radically restructured or disappear. Software is released in new versions, which may not be (fully) compatible with resources created using the earlier versions. Recording media for digital resources also deteriorates, often with data loss. Some resources are designed for use with specific hardware – which may breakdown, perhaps irretrievably, and/or go out of production.
This combination of factors means that you need to consider the preservation aspects of these resources at the earliest possible moment – ideally before they are created.
Before You Create a Policy
Before creating your policy on digital preservation you should first address the following issues:
- Listing of resources
- All types of digital resources that you either currently or plan to create, own or subscribe to should be documented.
- Identification
- Document the risks for each type of resource – e.g. Web site changes, software version changes, media degradation, hardware failure and replacement unavailability.
- Implications
- Consider the implications for your service in the worst case scenario. Are the resources intended to be ephemeral or permanent?
- Assessment
- Assess the value of groups of resources and the impact on your service if these no longer exist or are inaccessible.
- Solutions
- For each case, identify what the options are, how much they will cost and what they will require in terms of staff time and skills.
- Decide
- Decide on the strategies which are most appropriate for each type of resource.
Preservation Strategies
An appropriate strategy will depend on the resource and the type of failure. Strategies include:
- Refresh
- Transfer data between two types of the same storage medium e.g. creating a new preservation CD from the previous one.
- Migrate
- Transfer data from one format (operating system, programming language) to another format so the resource remains functional and accessible e.g. conversion from Microsoft Word to PDF or OpenDocument.
- Replicate
- Create one or more duplicates as insurance against loss or damage to one or more of the copies e.g. back-up copies on CD for resources available from Web site.
- Emulate
- Replicate the functionality of an obsolete application, operating system or hardware platform e.g. emulating WordPerfect 1.0 on a Macintosh system.
Your Preservation Policy
Having done the preparatory work, you are now in the position to be able to make decisions on your preservation policy, based on your particular combination of digital resources, funding, and technical platform and skills. Having made the decisions, record them and make sure all appropriate staff have access to the information.
The key characteristics of a preservation policy are:
- Clarity
- Different digital resources will require different preservation strategies. Deal with each type separately within the policy.
- Risks
- Each digital resource type is listed with its attendant risk.
- Solution
- The solution currently to be applied in the context of a specific (set of) resource(s).
- Revision
- As circumstances change, the preservation policy will need to change too, so build in a regular review.
Acknowledgements
This document was based on materials produced by the JISC-funded PoWR (Preservation of Web Resources) project which was provided by UKOLN and ULCC (University of London Computer Centre).
Filed under: Digital Preservation | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Management Issues
It is important that managers and governing bodies are fully aware of the implications of a digitisation project, especially the need to maintain resources beyond the project. Managers need to have sufficient knowledge to devise and implement relevant policies and procedures including a training plan.
Staff and Volunteers
Digitisation projects often require the recruitment of staff or volunteers. At the implementation stage these are some valuable skills including (a) awareness of general issues in digitisation; (b) practical digitisation skills and experience; (c) broader organisational skills; (d) methodical approach; (e) keyboard skills; (f) experience of databases, collections management systems, image management software; (g) ability to apply due care in handling museum objects and (h) discrimination in relevant areas e.g. visual (ability to distinguish colours), audio (awareness of background sounds).
Production may be in-house, through shared hardware and personnel, or using an external digitisation company.
Location
A separate photographic, audio or video studio is ideal. If museum objects are to be kept in the studio then security will need to be in line with that of stores. Control over movement of works of art should follow Spectrum standards.
Hardware
Hardware is a general term to describe the equipment needed for digitisation such as scanners, cameras (still and video), and audio and video recorders. The choice of equipment will be dictated by the scale and ambition of the project. The gap between consumer and professional equipment is becoming less well-defined.
Digitisation Strategy – Selecting Suitable Approaches
2D and 3D material may be captured in digital format through scanning or digital photography. The table below illustrates possible approaches.
| Originals |
Method |
Resolution / Colour Depth |
Notes |
Letters and line art
(Black & white) |
Flatbed scanner or digital camera |
600 dpi
1-bit |
The high resolution aids legibility.
You may want to capture these in colour to be more naturalistic e.g. to communicate the colour of the paper. |
Illustrations & maps
(Colour or black & white) |
Flatbed scanner or digital camera |
300 dpi, 8-bit grayscale or 24-bit colour. |
The lower resolution should be adequate but may need to be tested ref legibility. |
| Photograph (Colour or black and white) |
Flatbed scanner |
300 dpi 24-bit colour |
|
| 35mm slides and negatives (Colour or black & white) |
Slide scanner or flatbed scanner with transparency adapter |
1200 dpi, 24-bit colour or 8-bit grayscale |
|
| 2D and 3D objects |
Digital camera |
300 dpi, 24-bit colour |
lack and white artists’ prints may be photographed in colour (see above). For 3D objects a number of alternate views may be taken to more fully represent the object |
Notes
- Resolution is that captured when scanned or photographed, lower resolutions may be used in publication.
- TIFF should used for capture (and/or archive), other formats such as PNG or JPEG may be used in publication.
- Black and white photographs may be in grey tones, and sometimes colours from chemical processes used, e.g. sepia prints, or from aging.
- Sizes will vary with the size in pixels and the content of the image.
Acknowledgements
 This document has been produced from information contained within the Renaissance East Midlands Simple Guide to Digitisation that was researched and written by Julian Tomlin and is available from http://www.renaissanceeastmidlands.org.uk/. We are grateful for permission to republish this document under a Creative Commons licence. Anyone wishing to republish this document should include acknowledgements to Renaissance East Midlands and Julian Tomlin.
This document has been produced from information contained within the Renaissance East Midlands Simple Guide to Digitisation that was researched and written by Julian Tomlin and is available from http://www.renaissanceeastmidlands.org.uk/. We are grateful for permission to republish this document under a Creative Commons licence. Anyone wishing to republish this document should include acknowledgements to Renaissance East Midlands and Julian Tomlin.
Filed under: Needs-checking, Project Planning | No Comments »
Posted on August 26th, 2010 by Brian Kelly
The Role of Planning
Digital media is well placed to be reused, and to be available for different applications e.g. as a source of images for marketing, a picture library resource or for an online collections database. There are several aspects to this:
- The formats of documents or data files, by following established standards, remain discoverable and usable
- The media that they reside on is stored safely, is reliable, is refreshed and is backed up securely.
- Systems are designed to remain available, affordable and are supported.
- Web sites are maintained and supported.
Strategies
The following strategies can be used in the preservation of digital assets:
- Refreshing:
- Media may need to be refreshed in line with its recommended life. A checking system may be put in place to identify problems.
- Migration:
- Data may need conversion of data into a more accessible format. This has the potential for the loss of data.
- Emulation:
- Where an emulator mimics the original software environment to allow data to be read.
Standards and File Formats
Using standard formats for data files (whether text, images, audio and video) will not prevent them being superseded but can help in maximising the opportunity for reuse.
Systems
There can be a breakdown of continuity in both hardware and software even if open standards are used. Systems that conform to standards (e.g. Spectrum for a collections management system) may ensure easier migration to a new system.
Media
In the life of the PC there have been rapid changes in removable data, from the original 5.25″ ‘floppy’ disk found in the earliest PCs, to the 3.5″ disk, CD, DVD and USB memory stick. Fixed or ‘hard’ disks have grown in size from being measured in megabytes to reaching terabytes.
Issues to consider regarding digital media include:
- Capacity:
- The increasing size of data files has put pressure on backups. Simple local backups may be made using multiple CDs or DVDs but such media is not likely to be reliable in the longer term.
- Reliability:
- Reputable brands of media should be chosen to maximise reliability. Different brands may be selected for different sets to protect from faulty batches. Media should be kept in a stable environment, away from dust and dirt and magnetic interference.
- Identification:
- Safe labelling is important to identify the purpose of the backups and the relationship to any digitisation programmes. This should take into account use beyond the immediate life of the project and the original personnel involved.
- Archive Copies:
- Should be handled as little as possible. Working copies should be used for regular access, such as for copying and publication.
- Remote Backups:
- To ensure safe-keeping, a remote backup outside of the building and immediate area is necessary. This may provide an opportunity to store the media in a specialist, supervised store.
Web Sites
Consideration needs to be taken of preservation and sustainability issues concerning Web sites. The design of the Web site should take into account how digital content may be used in other applications, rather than being focussed solely on one output.
There is a clear advantage in storing and managing digital assets within a collections management system which has the capability of exporting to the Web as data might be more easily migrated to another system.
Acknowledgements
 This document has been produced from information contained within the Renaissance East Midlands Simple Guide to Digitisation that was researched and written by Julian Tomlin and is available from http://www.renaissanceeastmidlands.org.uk/. We are grateful for permission to republish this document under a Creative Commons licence. Anyone wishing to republish this document should include acknowledgements to Renaissance East Midlands and Julian Tomlin.
This document has been produced from information contained within the Renaissance East Midlands Simple Guide to Digitisation that was researched and written by Julian Tomlin and is available from http://www.renaissanceeastmidlands.org.uk/. We are grateful for permission to republish this document under a Creative Commons licence. Anyone wishing to republish this document should include acknowledgements to Renaissance East Midlands and Julian Tomlin.
Filed under: Digital Preservation | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Principles
Depending on the scale of the project, certain project planning tools and approaches should be applied since digitisation is likely to be seen as a discrete project, rather than purely an operational process.
Perhaps the first and potentially most useful is to outline the scope of the project. This can be done using mind mapping software which allows you to explore different elements of the project through a web of ideas.
Long-Term Issues
It is important to consider the long-term aspects of any decisions:
- Would it be better to go broader and digitise more objects in a simpler manner, or deeper by digitising at the highest possible quality?
- Might this form part of a strategy to digitise further sections of the collection?
- Are further resources likely to become available to pursue the above?
Factors in Selecting Material for Digitisation
It is important to establish copyright from the outset of your project as this may take a significant amount of time, and influence the viability of the project. If copyright cannot be traced then suitable records should be kept of attempts to establish copyright. You may then choose to publish uncleared material ‘at risk’. Legal advice should be sought if you are in any doubt.
Permission
Decisions will be informed by:
- Collection Factors:
- The condition of the objects; their importance and relevance; whether a selection would be sufficient and more realistic than digitising a complete collection; their relationship to other published collections. Is this part of a strategy to publish a certain area of the collection, for instance, and the need to reduce handling while providing access through digital surrogates.
- Human Resources:
- Will staff or volunteers need recruiting and do they have the necessary skills or is there a need for training?
- Equipment issues:
- Should digitisation take place externally through a specialist service? Is equipment available in-house or through a partner?
- Standards:
- What standards are to be used?
- Rights:
- Do you have rights over the material to be digitised?
- Sustainability:
- How will the digital resource be sustained, especially beyond the timescale of the project?
Project Planning Tools
Common project management tools include the following:
- A SMART analysis. Projects should be SMART i.e. Specific, Measurable, Achievable, Realistic and Timebound.
- Project Justification: Why are you doing this?
- Project Plan: Examining resources. A feasibility study may come first.
- Work Breakdown Structure: Defining tasks and sub-tasks.
- PERT (Project Evaluation and Review Technique) model: Analysis of tasks, timescales and interdependencies.
- GANTT Chart (named after Henry Gantt): A table listing tasks set against the project timescale, with milestones.
Involving Your Users/Evaluation
There should be evidence of demand for the digital assets that you are planning to create. This may be available, for example in having a large number of enquiries for a particular collection, if not it should be tested.
In order to ensure that your resource delivers its intended outcomes as effectively as possible, it is a good idea to start with the needs of the end user in mind, basing the design and structure of your resource on how they will use it. If this is a Web site, once you have defined your own objectives (i.e. why you want to do it, what it will help you to achieve), you should consider: (a) Who the site is for and who do you want to use it? (b) What are these users’ needs from the site: what will they want to do, and why? (c) How will they be using the site? and (d) What do you want users to get from their visit?
Acknowledgements
This document has been produced from information contained within the Renaissance East Midlands Simple Guide to Digitisation that was researched and written by Julian Tomlin and is available from http://www.renaissanceeastmidlands.org.uk/. We are grateful for permission to republish this document under a Creative Commons licence. Anyone wishing to republish this document should include acknowledgements to Renaissance East Midlands and Julian Tomlin.
Filed under: Needs-checking, Project Planning | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About Copyright
Copyright is a type of intellectual property that protects artistic works such as literature, music, art and recordings. It provides protection for creators as well as publishers. It is also important for publishers, such as museums, to protect themselves against breaches of copyright.
Copyright varies country by country although there is increasing harmonisation within the EU, and international treaties cover many countries.
There is no need to register copyright.
Some key facts relating to UK law:
- In a literary, musical or artistic work (including a photograph), copyright lasts until 70 years after the death of the creator.
- In sound recordings and broadcasts copyright usually belongs to the producer, broadcaster or publisher.
- Sound recordings are generally protected for 50 years from the year of publication. Broadcasts are protected for 50 years.
These guidelines are an interpretation of UK law. Please take appropriate legal advice before making any significant decisions regarding copyright of resources used in your service or project.
Establishing Copyright
It is important to establish copyright from the outset of your project as this may take a significant amount of time, and influence the viability of the project. If copyright cannot be traced then suitable records should be kept of attempts to establish copyright. You may then choose to publish uncleared material ‘at risk’. Legal advice should be sought if you are in any doubt.
Permission
For material in copyright, you should seek permission from the creator or copyright holder. This will relate to particular uses, for instance in a guidebook or on the museum’s web site.
There are some exceptions to the copyright owner’s rights. For example, you may be allowed limited copying of a work for non-commercial research and private study, criticism or review, reporting current events, and teaching in schools. The copyright holder should still be acknowledged and there are limits in terms of the number of copies and for large amounts of material.
Safeguarding Copyright
Since placing material on the web makes it easier for people to easily reuse it, you should consider ways of safeguarding your copyright.
Common ways are to make users register to use material, publish only low-resolution images, and imbed digital watermarks.
You may judge that while these approaches might help protect misuse they will also limit what might be considered to be unharmful usage. Low-resolution images may still be good enough for many uses, but are not generally good enough for paper-based publications. Digital watermarks can be removed by expert users.
Certainly, restricting some services to registered users may be appropriate for a comprehensive high-profile service such as SCRAN, the Scottish online learning resource, but for a smaller site this approach could be off-putting for the majority of users and still not prevent misuse.
You may chose to licence your digital assets through a Creative Commons licence which provides a more open approach to rights.
Acknowledgements
This document has been produced from information contained within the Renaissance East Midlands Simple Guide to Digitisation that was researched and written by Julian Tomlin and is available from http://www.renaissanceeastmidlands.org.uk/. We are grateful for permission to republish this document under a Creative Commons licence. Anyone wishing to republish this document should include acknowledgements to Renaissance East Midlands and Julian Tomlin.
Filed under: Legal Issues, Needs-checking | No Comments »
Posted on August 26th, 2010 by Brian Kelly
What Is Video Micro-blogging?
Twitter has been described as a micro-blogging application which allows users to publish short (<140 characters) snippets of text [1]. Video micro-blogging is similar but allows users to publish short (often less than 5 minute) video clips.
What Is Seesmic?
Seesmic [2] is an example of a video micro-blogging service. Users can record video clips directly from the Seesmic Web site (no additional software needs to be installed). Alternatively video clips can be uploaded or retrieved from sites such as YouTube.
The video clips can be viewed directly on the Seesmic Web site (as shown below and available at <http://seesmic.tv/videos/9E6jdYm8kF> or embedded in other Web pages.
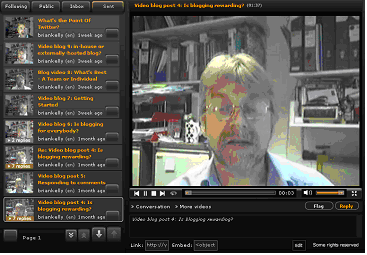
The screen shot shown above is of a video clip lasting 1 minute 27 seconds asking whether blogging can be rewarding. It should be noted that seven video responses to this post have been received.
Uses Of Seesmic
Sceptics argue that, unlike micro-blogging applications such as Twitter, video micro-blogging ser vices such as Seesmic are difficult to process quickly, as it is not possible to quickly digest the content or skim through video content.
Seesmic fans argue that use of video can provide a richer form of engagement with the publisher of the post. A blog post on the UK Web Focus blog describes the potential for use of Seesmic as a mechanism for creating content for use in presentations, for reviewing such content and for encouraging others to provide feedback which can be used in presentations [3].
Viewing Seesmic Posts Using Twhirl
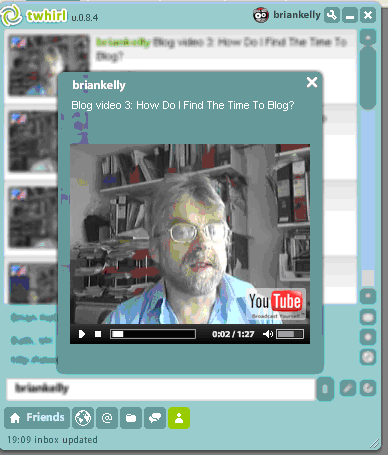 Seesmic video posts can be viewed using a Web browser, either by visiting the Seesmic Web site or by viewing a Seesmic video post which has been embedded in a Web page.
Seesmic video posts can be viewed using a Web browser, either by visiting the Seesmic Web site or by viewing a Seesmic video post which has been embedded in a Web page.
In addition a dedicated Seesmic client, such as Twhirl [4], can be used to view the video clips.
Twhirl was developed as a client for reading Twitter micro-blog posts. However it can also be used to view micro-blog posts from other services and video blog posts from Seesmic, as illustrated. An advantage with this approach is that new video posts from Seesmic users you are following will automatically be displayed in the Twhirl interface.
What Can Video Microblogging Services Offer?
It is too early to say whether video microblogging services such as Seesmic will have a significant impact. However as there is low cost to using Seesmic and it can allow users to gain experience in creating videos it may be a useful service for evaluating.
References
- An Introduction to Twitter, UKOLN Cultural Heritage Briefing Document No. 36,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-36/>
- Seesmic,
<http://www.seesmic.com/>
- Experiments With Video Blogging To Support Presentations, UK Web Focus blog, 10 Oct 2008,
<http://ukwebfocus.wordpress.com/2008/10/10/experiments-with-video-blogging/>
- Twhirl,
<http://www.twhirl.org/>
Filed under: Microblogs | No Comments »
Posted on August 26th, 2010 by Brian Kelly
What Is Micro-blogging?
Micro-blogging is defined in Wikipedia as “a form of blogging that allows users to write brief text updates (usually 140 characters) and publish them, either to be viewed by anyone or by a restricted group which can be chosen by the user. These messages can be submitted by a variety of means, including text messaging, instant messaging, email, MP3 or the Web” [1] [2]. Popular examples of micro-blogging services include Twitter and FriendFeed.
What Is Twitter?
Twitter, the most popular example of a micro-blogging service was launched in July 2006. Twitter allows users (who can register for free) to send brief posts (sometimes known as ‘tweets‘) which can be up to 140 characters long. The tweets are displayed on the users profile page and are delivered to users who have chosen to receive them by following the users’ tweets. Readers of a user’s tweets are referred to as ‘followers‘.
Although the tweets will be delivered to a user’s followers, the tweets can normally be accessed by anyone, even users who have not signed up to Twitter. They are published on the user’s Twitter home page and can also be accessed by an RSS feed.
Twitter Clients
 For many the initial experience with a micro-blogging service is Twitter. Initially many users will make use of the Twitter interface provided on the Twitter Web site. However regular Twitter users will often prefer to make use of a dedicated Twitter client, either on a desktop PC or one a mobile device such as an iPhone or iPod Touch.
For many the initial experience with a micro-blogging service is Twitter. Initially many users will make use of the Twitter interface provided on the Twitter Web site. However regular Twitter users will often prefer to make use of a dedicated Twitter client, either on a desktop PC or one a mobile device such as an iPhone or iPod Touch.
As well as allowing tweets to be read and posted Twitter clients often allow Twitter followers to be put into groups, Twitter posts content searched, etc.
The Echfon iPod application [3] and the Twhirl [4] and TweetDeck applications for the PC [5] are both popular. An example of how TweetDeck is being used is described at [6].
Use Of Twitter
Examples of uses of Twitter in the cultural heritage sector include:
- Brooklyn Museum
- A pioneer in the museum sector. See <http://twitter.com/brooklynmuseum>
- Scottish Library and Information Council (SLIC) and CILIP in Scotland
- See <http://twitter.com/scotlibraries>
- Organisers of the Museums and the Web 2009 Conference
- Use of Twitter to support its annual conference. See <http://twitter.com/mw2009>
- The Getty Museum
- See <http://twitter.com/GettyMuseum>
As can be seen from these examples and articles at [7], [8] Twitter can be used by professional bodies and institutions as well as by individuals.
Getting Started With Twitter
If you wish to evaluate Twitter either to support individual interests or those of your organisation you would be advised to register and allow yourself a period of several weeks in order to give you time to ‘get Twitter’ [6]. Remember that you will probably need to follow a critical mass of Twitter users to gain tangible benefits and you will also need to post as well as read tweets to gain the benefits of membership of a viable Twitter community. You should also remember that Twitter may not be for you – you do not need to use Twitter; rather you should be able to use it if it is beneficial.
References
- Micro-blogging, Wikipedia,
<http://en.wikipedia.org/wiki/Micro-blogging>
- An Introduction to Micro-blogging, UKOLN Cultural Heritage Briefing Document No. 35,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-35/>
- EchoFon, <http://www.twitterfon.com/>
- Twhirl,
<http://www.twhirl.org/>
- TweetDeck,
<http://www.tweetdeck.com/beta/>
- Getting Twitter, UK Web Focus blog, 21 Oct 2008,
<http://ukwebfocus.wordpress.com/2008/10/21/getting-twitter/>
- Learning from our Twitter xperiment,Lynda Kelly, 20 Aug 2008,
<http://museum30.ning.com/profiles/blogs/2017588:BlogPost:9689>
- Twitter for Librarians: The Ultimate Guide, 27 May 2008,
<http://www.collegeathome.com/blog/2008/05/27/twitter-for-librarians-the-ultimate-guide/>
Filed under: Microblogs, Needs-checking | No Comments »
Posted on August 26th, 2010 by Brian Kelly
What Is Micro-blogging?
Micro-blogging is defined in Wikipedia as “a form of blogging that allows users to write brief text updates (usually 140 characters) and publish them, either to be viewed by anyone or by a restricted group which can be chosen by the user. These messages can be submitted by a variety of means, including text messaging, instant messaging, email, MP3 or the Web” [1].
Popular examples of micro-blogging services include Twitter and FriendFeed. In additional the status feature of social networking services such as Facebook provides another example of micro-blogging.
What Is Video Micro-blogging?
Video micro-blogging is the multimedia equivalent, whereby short video posts can be published. The best-known example of a video micro-blogging service is Seesmic [2].
What Benefits Can Micro-Blogging Provide?
Rather than seeking to describe potential uses of micro-blogging tools such as Twitter, it may be preferable to provide analogies for their use. As described at [3] micro-blogging tools such as Twitter can be regarded as:
- The bar where everybody knows your name.
- An interactive business card (see [4]).
- A room of experts who can respond to your queries (see [5]).
- A room of friends who can listen to your concerns.
- A room of strangers who can sometimes surprise you.
- A digital watercooler, particular useful for home workers to share office gossip.
Other potential benefits include:
- Listening into announcements, discussions or informal conversations about your organisation or the services provided by your organisation.
- Providing business intelligence related to your peers, your funders or, in some circumstances, perhaps, competing organisations.
Micro-blogging can be regarded as a tool which can support a community of practice by providing a forum for work-related discussions and informal chat.
The Downside To Microblogging
A superficial look at Twitter might lead to the conclusions that micro-blogging services such as Twitter provides nothing more than trivial content and has no relevance to the information professional. However many Twitter users who have chosen to spend time in exploring its potential benefits. Twitter, like blogs, can be used for a variety of purposes although it also has the potential to be used as a communications medium, with Twitter users asking questions and discussing issues. In this respect Twitter has some parallels with chat rooms. But as with chat rooms, Instant Messaging, email and Web sites such tools can be counter-productive if used for inappropriate uses and if used excessively or to the detriment of other work activities.
Developing Good Practices For Micro-blogging
A simplistic response to potential misuses of micro-blogging tools would be to ban its use. However this approach would result in staff missing out on the benefits of making use of informal contacts and your organisation exploiting the benefits described above.
If you feel there is a need to establish a policy covering use of micro-blogging you might wish to ask whether you trust your staff to use such technologies in an appropriate fashion. And if you feel there is a need to implement such policies remember that staff can misuse their time at work in other ways which do not need access to technologies. Perhaps the best advice would be to ensure that you keep up-to-date with examples of effective use of micro-blogging [5] and ways of appreciated its benefits [6]. Managers should also encourage their staff to be innovative.
References
- Micro-blogging, Wikipedia,
<http://en.wikipedia.org/wiki/Micro-blogging>
- An Introduction to Seesmic, UKOLN Cultural Heritage Briefing Document No. 37,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-37/>
- Twitter, microblogging and living in the stream, The Edtechie Blog, 9 Sep 2008,
<http://nogoodreason.typepad.co.uk/no_good_reason/2008/09/twitter-microblogging-and-living-in-the-stream.html>
- Twitter? It’s An Interactive Business Card, UK Web Focus blog, 17 Apr 2008,
<http://ukwebfocus.wordpress.com/2008/04/17/twitter-its-an-interactive-business-card/>
- What Can Web 2.0 Offer To The IAMIC Community?, UK Web Focus blog, 22 Sep 2008,
<http://ukwebfocus.wordpress.com/2008/09/22/what-can-web-20-offer-to-the-iamic-community/>
- Getting Twitter, UK Web Focus blog, 21 Oct 2008,
<http://ukwebfocus.wordpress.com/2008/10/21/getting-twitter/>
Filed under: Microblogs, Needs-checking | No Comments »
Posted on August 26th, 2010 by Brian Kelly
What is a Creative Commons?
Creative Commons (CC) [1] refers to a movement started in 2001 by US lawyer Lawrence Lessig that aims to expand the collection of creative work available for others to build upon and share. The Creative Commons model makes a distinction between the big C (Copyright) meaning All Rights Reserved and CC meaning Some Rights Reserved. It does so by offering copyright holders licences to assign to their work, which will clarify the conditions of use and avoid many of the problems current copyright laws pose when attempting to share information.
What Licences?
There are a series of eleven Creative Commons licences available to download from the Web site. They enable copyright holders to allow display, public performance, reproduction and distribution of their work while assigning specific restrictions. The six main licences combine the four following conditions:
 |
Attribution – Users of your work must credit you. |
 |
Non-commercial – Users of your work can make no financial gain from it. |
 |
Non-derivative – Only verbatim copies of your work can be used. |
 |
Share-alike – Subsequent works have to be made available under the same licence as the original. |
The other licences available are the Sampling licence, the Public Domain Dedication, Founders Copyright, the Music Sharing licence and the CC Zero licence. Creative Commons also recommends two open source software licences for those licensing software: the GNU General Public licence and the GNU Lesser Public licence.
Each license is expressed in three ways: (1) legal code, (2) a commons deed explaining what it means in lay person’s terms and (3) a machine-readable description in the form of RDF/XML (Resource Description Framework/Extensible Mark up Language) metadata. Copyright holders can embed the metadata in HTML pages.
International Creative Commons
The Creative Commons licences were originally written using an American legal model but through the Creative Common international (CCi) have since been adapted for use in a number of different jurisdictions. As of April 2009 52 jurisdictions have completed licences and 7 jurisdictions licences are being developed.
The regional complexities of UK law has meant that two different set of licences have had to be drafted for use of the licenses the UK. Creative Commons worked with the Arts and Humanities Research Board Centre for Studies in Intellectual Property and Technology Law at Edinburgh University on the Scotland jurisdiction-specific licenses completed December 2005 (version 2.5) and the Information Systems and Innovation Group (ISIG) to create the England and Wales jurisdiction-specific licenses completed April 2005 (version 2.0).
Why Use Creative Commons Licences?
There are many benefits to be had in clarifying the rights status of a work. When dealing with Creative Commons licenced work, it is known if the work can be used without having to contact the author, thus allowing the work to be exploited more effectively, more quickly and more widely, whilst also increasing the impact of the work. Also in the past clarification of IPR has taken a huge amount of time and effort, Creative Commons could save some projects a considerable amount of money and aid their preservation strategies. More recently, because Creative Commons offers its licence in a machine-readable format, search engines can now search only CC licenced resources allowing users easier access to ‘free materials’.
Issues
Although Creative Commons has now been in existence for a while there are still issues to be resolved. For example in the UK academic world the question of who currently holds copyright is a complex one with little commonality across institutions. A study looking at the applicability of Creative Commons licences to public sector organisations in the UK has been carried out [2].
Another key area for consideration is the tension between allowing resources to be freely available and the need for income generation. Although use of a Creative Commons license is principally about allowing resources to be used by all, this does not mean that there has to be no commercial use. One option is dual licensing, which is fairly common in the open source software environment.
References
- Creative Commons,
<http://creativecommons.org/>
- Creative Commons Licensing Solutions for the Common Information Environment, Intrallect,
<http://www.intrallect.com/cie-study/>
Filed under: Legal Issues, Needs-checking | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This document provides top tips which can help to ensure that Web sites can be preserved.
The Top 10 Tips
- 1 Define The Purpose(s) Of Your Web Site
- You should have a clear idea of the purpose(s) of your Web site and you should document the purposes. Your Web site could, for example, provide access to project deliverables for end users; could provide information about the project; could be for use by project partners; etc. A policy for preservation will be dependent of the role of the Web site.
- 2 Have A URI Naming Policy
- Before launching your Web site you should develop a URI naming policy. Ideally you should contain the project Web site within its own directory, which will allow the project Web site to be processed (e.g. harvested) separately from other resources on the Web site.
- 3 Think Carefully Before Having Split Web Sites
- The preservation of a Web site which is split across several locations may be difficult to implement. However also bear in mind tip 4.
- 4 Think About Separating Web Site Functionality
- On the other hand it may be desirable to separate the functionality of the Web site, to allow, for example, information resources to be processed independently of other aspects of the Web site. For example, the search functionality of the Web site could have its own sub-domain,(e.g. search.foo.ac.uk) which could allow the information resources (under www.foo.ac.uk) to be processed separately.
- 5 Make Use Of Open Standards
- You should seek to make use of open standard formats for your Web site. This will help you to avoid lock-in to proprietary formats for which access may not be available in the future. However you should also be aware of possible risks and resource implications in using open standards.
- 6 Explore Potential For Exporting Resources From A CMS
- You should explore the possibility of exporting resources from a backend database or Content Management Systems in a form suitable for preservation. When procuring a CMS you should seek to ensure that such functionality is available.
- 7 Be Aware Of Legal, IPR, etc. Barriers To Preservation
- You need to be aware of various legal barriers to preservation. For example, do you own the copyright of resources to be preserved; are there IPR issues to consider; are confidential documents (such as project budgets, minutes of meetings, mailing list archives, etc.) to be preserved; etc.
- 8 Ensure Institutional Records Managers Provide Input
- You should ensure that staff from your institution’s records management teams provide input into policies for the preservation of Web site resources.
- 9 Provide Documentation
- You should provide technical documentation on your Web site which will allow others to preserve your Web site and to understand any potential problem areas. You should also provide documentation on your policy of preservation.
- 10 Share Your Experiences
- Learn from the experiences of others. For example read the case study on Providing Access to an EU-funded Project Web Site after Completion of Funding [1] and the briefing document on Mothballing Web Sites [2].
References
Filed under: Digital Preservation, Needs-checking | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This briefing document provides an introduction to digital preservation.
What Is Digital Preservation?
Digital preservation is the management of digital information over time. It takes the form of processes and activities that ensure continued access to information and all kinds of records, both scientific and cultural heritage, that exists in digital form.
The aim of digital preservation is long-term, error-free storage of digital information, with the means of retrieval and interpretation, for the period of time that information is required.
Why Do We Need Digital Preservation?
The digital world is a place of rapid technological and organisational changes, which impacts on the continuing use of digital resources. In contrast to our physical written heritage, still readable today, digital information created only a few years ago is in danger of being lost.
Which Materials Need Preservation?
All types of digital resources need preservation including:
- Digitally Reformatted
- Digitised versions or surrogates of physical items.
- Born Digital
- Digital resources that have no analogue counterpart.
- Individual resources
- Texts, still and moving images, sound recordings, etc.
- Collective resources
- Web sites, e-journals, wikis, catalogues, etc.
- Data Sets
- Scientific and cultural data comprising multiple individual pieces of data.
- Communication record
- For example, email, instant messages, etc.
Preservation Metadata
The long-term storage of digital information is assisted by the inclusion of preservation metadata which records various features of the resource. For example:
- Format
- MS Word or Notepad? MS Word 2 or MS Word 6? JPEG or GIF?
- Version
- Pre-print, published.
- Playback
- Equipment or emulation device required.
Issues
Digital preservation encompasses a range of strategies, processes and activities, with a variety of associated issues to be considered. Examples are:
- Long-term
- May extend indefinitely and depends on the need for continuing access to a resource in one or more specific formats. The lifetime of a specific resource is determined by the degradation and/or format accessibility of that resource.
- Retrieval
- Obtaining digital files from storage without corrupting the stored files.
- Interpretation
- The digital files must be decoded and transformed into usable representations, for machine processing and/or human access.
- Rendering
- Making a digital file available for a human to access.
- Re-digitising
- Some early digitised resources are in formats that are, or are rapidly becoming, obsolete. Since it can be the case that poor results are obtained by migrating from the obsolete format to a newer format, it may sometimes be better to re-digitise from the original.
- Emulation
- Where specific playback equipment is no longer available, emulation software may need to be written in order to access the informational content using a different device.
- Degradation
- The process by which parts of a resource are lost over time. This may occur as a characteristic of a format (it becomes a less accurate representation over time) or a consequence of copying from another file or migrating from one format to another.
- Effort
- It appears that digital preservation requires more frequent and ongoing action than other types of media. The consequent requirement in terms of effort, time and money is a major stumbling block for preserving digital information.
Filed under: Digital Preservation | No Comments »
Posted on August 26th, 2010 by Brian Kelly
An Introduction To Digital Preservation
About This Document
This briefing document provides an introduction to digital preservation.
What Is Digital Preservation?
Digital preservation is the management of digital information over time. It takes the form of processes and activities that ensure continued access to information and all kinds of records, both scientific and cultural heritage, that exists in digital form.
The aim of digital preservation is long-term, error-free storage of digital information, with the means of retrieval and interpretation, for the period of time that information is required.
Why Do We Need Digital Preservation?
The digital world is a place of rapid technological and organisational changes, which impacts on the continuing use of digital resources. In contrast to our physical written heritage, still readable today, digital information created only a few years ago is in danger of being lost.
Which Materials Need Preservation?
All types of digital resources need preservation including:
- Digitally Reformatted
- Digitised versions or surrogates of physical items.
- Born Digital
- Digital resources that have no analogue counterpart.
- Individual resources
- Texts, still and moving images, sound recordings, etc.
- Collective resources
- Web sites, e-journals, wikis, catalogues, etc.
- Data Sets
- Scientific and cultural data comprising multiple individual pieces of data.
- Communication record
- For example, email, instant messages, etc.
Preservation Metadata
The long-term storage of digital information is assisted by the inclusion of preservation metadata which records various features of the resource. For example:
- Format
- MS Word or Notepad? MS Word 2 or MS Word 6? JPEG or GIF?
- Version
- Pre-print, published.
- Playback
- Equipment or emulation device required.
Issues
Digital preservation encompasses a range of strategies, processes and activities, with a variety of associated issues to be considered. Examples are:
- Long-term
- May extend indefinitely and depends on the need for continuing access to a resource in one or more specific formats. The lifetime of a specific resource is determined by the degradation and/or format accessibility of that resource.
- Retrieval
- Obtaining digital files from storage without corrupting the stored files.
- Interpretation
- The digital files must be decoded and transformed into usable representations, for machine processing and/or human access.
- Rendering
- Making a digital file available for a human to access.
- Re-digitising
- Some early digitised resources are in formats that are, or are rapidly becoming, obsolete. Since it can be the case that poor results are obtained by migrating from the obsolete format to a newer format, it may sometimes be better to re-digitise from the original.
- Emulation
- Where specific playback equipment is no longer available, emulation software may need to be written in order to access the informational content using a different device.
- Degradation
- The process by which parts of a resource are lost over time. This may occur as a characteristic of a format (it becomes a less accurate representation over time) or a consequence of copying from another file or migrating from one format to another.
- Effort
- It appears that digital preservation requires more frequent and ongoing action than other types of media. The consequent requirement in terms of effort, time and money is a major stumbling block for preserving digital information.
Filed under: Digital Preservation | No Comments »
Posted on August 26th, 2010 by Brian Kelly
What Is A Mashup?
Wikipedia defines a mashup as “a web application that combines data from more than one source into a single integrated tool” [1]. Many popular examples of mashups use the Google Map service to provide a location display of data taken from another source.
Technical Concepts
As illustrated in a video clip on “What Is A Mashup?” [2] from a programmer’s perspective a mashup is based on making use of APIs (application programmers interface). In a desktop PC environment, application programmers make use of operating system functions (e.g. drawing a shape on a screen, accessing a file on a hard disk drive, etc.) to make use of common functions within the application they are developing. A key characteristic of Web 2.0 is the notion of ‘the network as the platform’. APIs provided by Web-based services (such as services provided by companies such as Google and Yahoo) can similarly be used by programmers to build new services, based on popular functions the companies may provide. APIs are available for, for example, the Google Maps service and the del.icio.us social book marking service.
Creating Mashups
Many mashups can be created by simply providing data to Web-based services. As an example, the UK Web Focus list of events is available as an RSS feed as well as a plain HTML page [3]. The RSS feed includes simple location data of the form:
<geo:lat>51.752747</geo:lat>
<long>-1.267138</geo:long>
This RSS feed can be fed to mashup services, such as the Acme.com service, to provide a location map of the talks given by UK Web Focus, as illustrated.
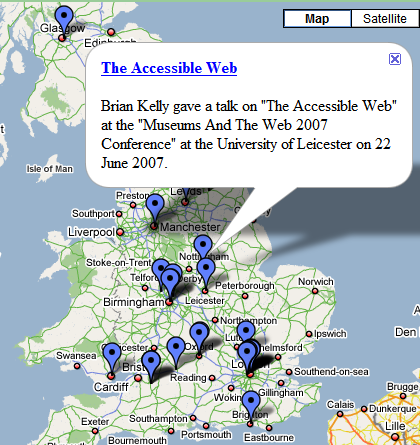
Tools For The Developer
More sophisticated mashups will require programming expertise. The mashup illustrated which integrates photographs and videos from Flickr and YouTube for a wide range of UK museums was produced as a prototype by Mike Ellis, a software developer [5].
However tools are being developed which will allow mashups to be created by people who may not consider themselves to be software developers – the best known is Yahoo Pipes [6] which “provides a graphical user interface for building data mashups that aggregate web feeds, web pages, and other services, creating Web-based apps from various sources, and publishing those apps” [7].
Allowing Your Service To Be ‘Mashed Up’
Paul Walk commented that “The coolest thing to do with your data will be thought of by someone else” [8]. Mashups provide a good example of this concept: if you provide data which can be reused, this will allow others to develop richer services which you may not have the resources or expertise to develop. It can be useful, therefore, to seek to both provide structured data for use by others and to avoid software development if existing tools already exist. However you will still need to consider issues such as copyright and other legal issues and service sustainability.
References
- Mashup (web application hybrid, Wikipedia,
<http://en.wikipedia.org/wiki/Mashup_(web_application_hybrid)>
- What is A Mashup?, ZDNet,
<http://news.zdnet.com/2422-13569_22-152729.html >
- Forthcoming Events and Presentations, UK Web Focus, UKOLN,
<http://www.ukoln.ac.uk/web-focus/events/>
- Location of UK Web Focus Event, UKOLN,
<http://www.acme.com/GeoRSS/?xmlsrc=http://www.ukoln.ac.uk/web-focus/events/presentations-2007.rss>
- Mashed Museum Director,
<http://www.mashedmuseum.org.uk/mm/museumdirectory/v3/>
- Yahoo Pipes, Yahoo,
<http://pipes.yahoo.com/pipes/>
- Yahoo Pipes, Wikipedia,
<http://en.wikipedia.org/wiki/Yahoo!_Pipes>
- The coolest thing to do with your data will be thought of by someone else, Paul Walk, 23 July 2007,
<http://blog.paulwalk.net/2007/07/23/>
Filed under: Needs-checking, Web 2.0 | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This briefing document describes the issues to be considered when choosing and using metadata.
Why Use Metadata?
Metadata cannot solve all your resource management and discovery problems but it can play an important part in the solutions. Since time and effort is needed if metadata is to be used effectively, it is vital to look closely at the problems you wish to address.
Do you want to allow resources on your Web site to be found more easily by search engines such as Google? Or perhaps you want to improve local searching on your Web site? Do you need interoperability with other projects and services? Maybe you want to improve the maintenance of resources on your Web site.
While metadata has a role to play in all of these situations, different approaches will be needed to tackle each type of problem. And in some cases, metadata may not be the optimal solution; for example, Google makes limited use of metadata so an alternative strategy might be needed.
Identifying the Functionality to be Provided
Once you have clarified why you want to use metadata, you should identify the end-user functionality you wish to provide. This will enable you to define the metadata you need, how it should be represented, and how it should be created, managed and deployed.
Choosing The Metadata Standard
You will need to choose the metadata standard which is relevant for your purpose. In many cases this will be self-evident. For example, a project that is funded to develop resources in an OAI environment will need to use the OAI application, while for a database of collection descriptions you will need to use collection description metadata.
Off the Shelf or Custom Fit?
Some metadata can be used without further work – for example, MARC 21 format in library management system cataloguing modules or entries in the Cornucopia and MICHAEL collection description databases.
Other metadata requires decisions on your part. If you are using Dublin Core, you will need to decide whether to use qualifiers (and if so which) and which elements are mandatory and which are repeatable.
Managing Your Metadata
It is important that you think about this at an early stage. If not properly managed, metadata can become out-of-date; and since metadata is not normally displayed to end-users but processed by software, you won’t be able to check visually. Poor quality data can be a major obstacle to interoperable services.
If, for example, you embed metadata directly into a file, you may find it difficult to maintain the metadata; e.g. if the creator changes their name or contact details. A better approach may be the use of a database (sometimes referred to as a metadata repository) which provides management capabilities.
Example Of Use Of This Approach
The Exploit Interactive e-journal was developed by UKOLN with EU funding. Metadata was required in order to provide enhanced searching for the end user. The specific functionality required was the ability to search by issue, article type, author and title and by funding body. In addition metadata was needed in order to assist the project manager producing reports, such as the numbers of different types of articles. This functionality helped to identify the qualified Dublin Core elements required.
The MS SiteServer software used to provide the service provided an indexing and searching capability for processing arbitrary metadata. It was therefore decided to provide Dublin Core metadata stored in <meta> tags in HTML pages. In order to allow the metadata to be more easily converted into other formats (e.g. XHTML) the metadata was held externally and converted to HTML by server-side scripts.
A case study which gives further information (and describes the limitations of the metadata management approach) is available.
Managing And Using Metadata In An E-Journal, QA Focus briefing document no. 1, UKOLN, <http://www.ukoln.ac.uk/qa-focus/documents/case-studies/case-study-01/>
Filed under: Metadata | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Introduction
Once you have decided to make use of metadata in your project, you then need to agree on the functionality to be provided, the metadata standards to be used and the architecture for managing and deploying your metadata. However this is not the end of the matter. You will also need to ensure that you have appropriate quality assurance procedures to ensure that your metadata provides fitness for its purposes.
What Can Go Wrong?
There are a number of ways in which services based on metadata can go wrong, such as:
- Incorrect content:
- The content of the metadata may be incorrect or out-of-date. There is a danger that metadata content is even more likely to be out-of-date than normal content, as content is normally visible, unlike metadata which is not normally displayed on, say, a Web page. In addition humans can be tolerant of errors, ambiguities, etc. in ways that software tools normally aren’t.
- Inconsistent content:
- The metadata content may be inconsistent due to a lack of cataloguing rules and inconsistent approaches if multiple people are involved in creating metadata.
- Non-interoperable content:
- Even if metadata is consistent within a project, other projects may apply different cataloguing rules. For example the date 01/12/2003 could be interpreted as 1 December or 12 January if projects based in the UK and USA make assumptions about the date format.
- Incorrect format:
- The metadata may be stored in a non-valid format. Again, although Web browsers are normally tolerant of HTML errors, formats such as XML insist on compliance with standards.
- Errors with metadata management tools:
- Metadata creation and management tools could output metadata in invalid formats.
- Errors with the workflow process:
- Data processed by metadata or other tools could become corrupted through the workflow. As a simple example a MS Windows character such as © could be entered into a database and then output as an invalid character in a XML file.
QA For Metadata Content
You should have procedures to ensure that the metadata content is correct when created and is maintained as appropriate. This could involve ensuring that you have cataloguing rules, ensuring that you have mechanisms for ensuring the cataloguing rules are implemented (possibly in software when the metadata is created). You may also need systematic procedures for periodic checking of the metadata.
QA For Metadata Formats
As metadata which is to be reused by other applications is increasingly being stored in XML it is essential that the format is compliant (otherwise tools will not be able to process the metadata). XML compliance checking can be implemented fairly easily. More difficult will be to ensure that metadata makes use of appropriate XML schemas.
QA For Metadata Tools
You should ensure that the output from metadata creation and management tools is compliant with appropriate standards. You should expect that such tools have a rich set of test suites to validate a wide range of environments. You will need to consider such issues if you develop your own metadata management system.
QA For Metadata Workflow
You should ensure that metadata does not become corrupted as it flows through a workflow system.
A Fictitious Nightmare Scenario
A multimedia e-journal project is set up. Dublin Core metadata is used for articles which are published. Unfortunately there are documented cataloguing rules and, due to a high staff turnover (staff are on short term contracts) there are many inconsistencies in the metadata (John Smith & Smith, J.; University of Bath and Bath University; etc.)
The metadata is managed by a home-grown tool. Unfortunately the author metadata is output in HTML as DC.Author rather than DC.Creator. In addition the tool output the metadata in XHTML 1.0 format which is embedded in HTML 4.0 documents.
The metadata is created by hand and is not checked. This results in a large number of typos and use of characters which are not permitted in XML without further processing (e.g. £, — and &).
Rights metadata for images which describes which images can be published freely and which is restricted to local use becomes separated from the images during the workflow process.
Filed under: Metadata | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This briefing document provides an introduction to Dublin Core metadata
What Is Dublin Core Metadata?
Identifying metadata elements in a standard way enables metadata to be processed in a consistent manner by computer software.
The Dublin Core Metadata Element Set is a standard for cross-domain information resource description. It is widely used to describe digital materials such as video, sound, image, text and composite media such as Web pages. It is the best known metadata standard in the Web environment.
Based on the Resource Description Framework, it defines a number of ‘elements’ of data that are required to find, identify, describe and access a particular resource.
Dublin Core metadata is typically recorded using Extensible Markup Language (XML).
Dublin Core is defined by ISO Standard 15836 and NISO Standard Z39.85-2007.
Simple Dublin Core
There are 15 core elements in the Dublin Core standard:
Title, Creator, Subject, Description, Contributor, Date, Type, Format, Identifier, Source, Language, Relation, Coverage and Rights.
Qualified Dublin Core
The core element set was deliberately kept to a minimum, but this sometimes proved a problem for early implementers. This led to the development of Qualified Dublin Core, which has a further 3 elements (Audience, Provenance and RightsHolder) and a set of element qualifiers, which restrict or narrow the meaning of an element.
For example, qualified Date elements are DateAccepted, DateCopyrighted and DateSubmitted.
Metadata Standards
Because so many communities now use metadata, there are a bewilderingly large number of standards and formats in existence or in development. Metadata is used for resource description and discovery; recording intellectual property rights and access data; and technical information relating to the creation, use and preservation of digital resources.
What Does It Look Like?
Dublin Core metadata is typically recorded in XML using <meta> tags. Each element has a label; this is recorded between <…> brackets and precedes the actual data, while another set of brackets and a forward slash <…> marks the end of the data.
Some examples are:
<Creator> Ann Chapman </Creator>
<Title> An Introduction to Dublin Core </Title>
<DateSubmitted> 20080417 </DateSubmitted>
<DateAccepted> 20080611 </DateAccepted>
<Relation> Cultural Heritage Briefing Papers series </Relation>
<Subject> Metadata </Subject>
<Format> Word document Office 2003 </Format>
<Language> English </Language>
Application Profiles
Implementers then found that even Qualified Dublin Core had insufficient detail for use in specific communities. This lack led to the development of Application Profiles which contain further elements and element qualifiers appropriate to the community of interest.
- DC-Lib
- Library Application Profile. Used to describe resources by libraries and library related applications and projects.
- DC-Collections
- Collections Application Profile. Used to describe resources at collection level.
- SWAP
- Scholarly Works Application Profile. Used to describe research papers, scholarly texts, data objects and other resources created and used within scholarly communications.
- DC-Education
- Education Application Profile. Used to describe the educational aspects of any resource, and/or the educational context within which is has been or may be used. It is intended to be usable with other application profiles.
Filed under: Metadata | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This briefing document provides an introduction to metadata.
What Is Metadata?
Metadata is sometimes defined literally as ‘data about data’. More usefully, the term is understood to mean structured data about resources. The fact that the data is structured – broken down into very specific pieces – enables a range of automated processes to be built around the data to provide services.
Traditional ‘Metadata’?
In one sense, metadata is not a new concept. Library catalogues, abstracting and indexing services, directories of resources and institutions, archival finding aids and museum documentation all contain structured information.
What is the Value of Metadata
Firstly, it enables librarians, archivists and museum documentation professionals to work across institutional and sector boundaries to provide more effective resource discovery to the benefit of enquirers, students and researchers.
Secondly, it enables cultural heritage professions to communicate more effectively with other domains that also have an interest in metadata, such as publishers, the recording industry, television companies, producers of digital educational content, software developers and those concerned with geographical and satellite-based information.
Metadata Standards
Because so many communities now use metadata, there are a bewilderingly large number of standards and formats in existence or in development. Metadata is used for resource description and discovery; recording intellectual property rights and access data; and technical information relating to the creation, use and preservation of digital resources.
Metadata Encoding
Metadata is recorded in formats (e.g. MARC 21) or implementations of Mark-up Languages and Document Type Definitions (DTD). The main standards are:
- SGML
- Standard Generalised Mark-up Language.
- XML
- Extensible Mark-up Language.
Metadata for Libraries
Important metadata standards for use in a library context are:
- MARC 21
- A means of encoding metadata defined in bibliographic cataloguing rules.
- ISBD series
- International Standard for Bibliographic Description.
- ONIX
- A range of international standards for electronic information messages (about books, serials and licensing and rights) for the book industry.
Metadata for Archives
Important metadata standards for use in an archives context are:
- EAD
- Encoded Archival Description; a means of encoding metadata defined in archival cataloguing rules.
- ISAD(G)
- International Standard for Archival Description.
Metadata for Museums
Important metadata standards for use in a museum context are:
- CIMI DTD
- Computer Interchange of Museum Information.
- SPECTRUM
- The UK and international standard for collections management.
Metadata for the Digital World
Important metadata standards for use in a digital context are:
- Dublin Core (DC)
- Defines 15 metadata elements for simple resource discovery. Qualifiers for some of these elements enable more detail to be recorded. Further elements have now been defined to use in specific fields.
- DC Application Profiles
- A set of DC elements defined for use in the context of specific communities of practice; for example, education, libraries, collections and scholarly works.
Filed under: Metadata | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This briefing document provides an introduction to using Collection Description metadata as a collection management tool.
Managing Collections
Many collections are in fact groupings of smaller collections. These smaller collections may have been bought, donated, acquired by exchange, or created through digitisation programmes. While organisations may think they know just what they have, in reality the next time someone asks a question about part of the collection, finding the answer can turn into quite a search.
Collection Description metadata provides a tool that enables all the information about a collection and its component sub-collections to be recorded in a structured way.
Lost Knowledge
A public library service was creating collection description records to add to a local area database. For some of the sub-collections there was little information actually recorded and former members of staff had to be contacted to fill in the gaps. Now that the information has been recorded, it is used not only as a collection management tool, but also in the induction process for new staff and as a look-up document at the enquiry desk.
Benefits
Collection Description metadata can be held in a private ‘staff access only’ database or in ‘not for public display’ fields in a public database. Keeping the information in such a database means staff can easily update entries as well as check specific details about a collection. A variety of information can be recorded: ownership and provenance, access conditions and IPR details, whether the collection is still being added to, how often and by what method. Some of these are detailed below.
Use and Re-use Information
This group of data elements captures information on:
- Who can use the collection for reference?
- Who can borrow items from the collection?
- Can the items be copied?
- Can the items be re-used in another resource?
Agent Information
This group of data elements captures information on:
- Who owns this collection now?
- Who owned it in the past?
- Who collected the items?
- Who manages the collection?
Acquisition Information
This group of data elements captures information on:
- Are items still being added to the collection?
- If yes, how often and by what method (buy, donation, exchange)?
- Was digitisation funded by an external grant?
- Is this collection part of another collection which has been split up (the findings of an archaeological dig, the exhibition which combined resources from several institutions)?
- Are the items on (temporary, long-term or permanent) loan from another institution or person?
Caution
As with any other reference source, a collection description database must be kept up to date and changes entered. An out-of date database will mean you have to track down those former members of staff again.
Filed under: Collection Description | No Comments »
Posted on August 26th, 2010 by Brian Kelly
What Is A Social Network?
Wikipedia defines a social network service as a service which “focuses on the building and verifying of online social networks for communities of people who share interests and activities, or who are interested in exploring the interests and activities of others, and which necessitates the use of software.” [1].
A report published by OCLC provides the following definition of social networking sites: “Web sites primarily designed to facilitate interaction between users who share interests, attitudes and activities, such as Facebook, Mixi and MySpace.” [2]
What Can Social Networks be Used For?
Social networks can provide a range of benefits to members of an organisation:
- Support for learning
- Social networks can enhance informal learning and support social connections within groups of learners and with those involved in the support of learning.
- Support for members of an organisation
- Social networks can potentially be used my all members of an organisation and not just those involved in working with students. Social networks can help the development of communities of practice.
- Engaging with others
- Passive use of social networks can provide valuable business intelligence and feedback on institutional services (although this may give rise to ethical concerns).
- Ease of access to information and applications
- The ease of use of many social networking services can provide benefits to users by simplifying access to other tools and applications. The Facebook Platform provides an example of how a social networking service can be used as an environment for other tools.
- Common interface
- A possible benefit of social networks may be the common interface which spans work / social boundaries. Since such services are often used in a personal capacity the interface and the way the service works may be familiar, thus minimising training and support needed to exploit the services in a professional context. This can, however, also be a barrier to those who wish to have strict boundaries between work and social activities.
Examples Of Social Networking Services
Examples of popular social networking services include:
- Facebook
- Facebook is a social networking Web site that allows people to communicate with their friends and exchange information. In May 2007 Facebook launched the Facebook Platform which provides a framework for developers to create applications that interact with core Facebook features [3].
- MySpace
- MySpace [4] is a social networking Web site offering an interactive, user-submitted network of friends, personal profiles, blogs and groups, commonly used for sharing photos, music and videos.
- Ning
- An online platform for creating social websites and social networks aimed at users who want to create networks around specific interests or have limited technical skills [5].
- Twitter
- Twitter [6] is an example of a micro-blogging service [7]. Twitter can be used in a variety of ways including sharing brief information with users and providing support for one’s peers.
Note that this brief list of popular social networking services omits popular social sharing services such as Flickr and YouTube.
Opportunities And Challenges
The popularity and ease of use of social networking services have excited institutions with their potential in a variety of areas. However effective use of social networking services poses a number of challenges for institutions including long-term sustainability of the services; user concerns over use of social tools in a work or study context; a variety of technical issues and legal issues such as copyright, privacy, accessibility; etc.
Institutions would be advised to consider carefully the implications before promoting significant use of such services.
References
- Social network service, Wikipedia,
<http://en.wikipedia.org/wiki/Social_network_service>
- Sharing, Privacy and Trust In Our Networked World, OCLC,
<http://www.oclc.org/reports/sharing/>
- Facebook, Wikipedia,
<http://en.wikipedia.org/wiki/Facebook>
- MySpace, Wikipedia,
<http://en.wikipedia.org/wiki/Myspace>
- Ning, Wikipedia,
<http://en.wikipedia.org/wiki/Ning>
- An Introduction To Twitter, UKOLN Cultural heritage briefing document no. 36,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-36/>
- An Introduction To Micro-Blogging, UKOLN Cultural heritage briefing document no. 35,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-35/>
Filed under: Social Networks | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This briefing document provides an introduction to Collection Description as a resource discovery tool.
Why Do We Need It?
Archives, libraries and museums each have their own approach to resource discovery. Traditionally libraries used catalogues to describe individual items, archives used finding aids which set items as an integral part of a collection, while museums arranged items in groupings for the visiting public but did not provide publicly accessible catalogues.
Now all three domains have digitised resources and users expect information on collections to be available. At collection level, users might be looking for:
- Images, sound recordings and/or text material on the use of a plant in herbal medicine – I’m creating a herb garden.
- Information about my family – I’m tracing my family history.
- Images relating to slavery in Bristol – for my history coursework.
Since 1991, a number of resources have been developed to help resource discovery at collection level. Some of these are described below.
Culture 24
Partly funded by the government this Web site promotes museums, galleries and heritage sites across the UK – see <http://www.culture24.org.uk/>.
- CULTURE24
- Event listings, collection information and venue details are held in a live database, that UK museums, galleries, libraries and museums can add to using passworded access.
- ShowMe
- Children’s zone that brings together interactive materials from collections across the UK.
MICHAEL
MICHAEL stands for “Multi-Lingual Inventory of Cultural Heritage in Europe”. The MICHAEL Web site is available at <http://www.michael-culture.org/en/home>.
- Partners
- The MICHAEL partners are France, Italy, UK. Phase 2: Czech Republic, Finland, Germany, Greece, Hungary, Malta, the Netherlands, Poland, Portugal, Spain and Sweden.
- UK entries
- Digital collections held by cultural heritage institutions. This service complements Cornucopia (described below) which holds details of physical collections.
Collection Description Databases
Some examples of collection description databases – each has a different focus:
- Cornucopia
- Initially this covered only physical museum collections in England; descriptions for library collections were added as part of the Inspire project. See <http://www.cornucopia.org.uk/>
- Cecilia
- The focus is on collections relating to music – everything from CDs to music scores and historic instruments to composers manuscripts. See <“http://www.cecilia-uk.org/>
- SCONE
- The Scottish Collections Network – materials held in Scotland and collections about Scottish issues held elsewhere. See <http://scone.strath.ac.uk/>
- PADDI
- Planning Architecture Design Database Ireland covers all aspects of the built environment and environmental planning in Ireland. See <http://www.paddi.net/>
- Tap Into Bath
- Cultural heritage and academic collections held in archives, museums, art galleries and libraries in the city of Bath. The database and software are available for free re-use. See <http://www.bath.ac.uk/library/tapintobath/>
- Southern Cross Resource Finder
- Describes UK-based collections that hold resources useful for the study of Australia and/or New Zealand. Uses the Tap into Bath database and software. See <http://www.scrf.org.uk/>
Filed under: Collection Description | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This briefing document provides a brief introduction to the concept of Collections.
What Is A Collection?
A collection is a group of resources that are related to each other in some identifiable way. The relationship might be through a topic, a place, a person, an organisation or a type of object.
A collection may be divided into smaller parts, or sub-collections, which may in turn be divided into smaller parts. For example, a library collection might be divided into fiction and non-fiction stock, with the non-fiction stock divided into lending and reference stock, while a museum might have collections of ceramics, textiles, coins and silverware, with the coins divided into categories or sub-collections by time period – Roman, Anglo-Saxon, medieval, etc.
How Many Items Make a Collection?
There is no minimum number of items for a collection – in theory it is possible to have a collection containing only one item! Collections can also be very large and, typically, large collections will divided into a number of sub-collections.
Physical or Digital?
The items in a collection can be physical (books, objects, paintings, etc.) or digital (e-books, digital images, databases). It is also possible for collections to be hybrids, and contain both physical and digital items. A collection may also contain digital items that are surrogates of physical items in that collection.
Whether physical, digital or a combination, the items do not have to be in the same location and can be distributed over multiple locations. Locations may also be a factor in creating sub-collections; a public library may have a number of branch libraries each with its own stock collection.
Permanent or Temporary?
A collection, whether physical, digital or combined, does not have to be a permanent resource. For example a collection of digital items may:
- exist only for the duration of a search – the results display
- be limited for a current subscription – an e-journals bundle
A collection of physical items may:
- have existed in the past but the individual items have been distributed to other permanent collections – the findings from an archaeological excavation
- be brought together from other collections on a temporary basis – an exhibition
Exclusive or Inclusive?
Items can belong to more than one collection or sub-collection at a time, although placed in a single physical location. A coin can be designated as part of a coin collection and part of the Roman collection. Likewise, a map could simultaneously be part of a library local studies collection, part of a maps collection and / or part of the reference collection. A donor bequest collection that either has no topic focus or has several could be split into several collections (theology, natural history, railways) but still retain its identity as a set of items collected and donated by someone.
Describing Collections using Metadata
The digitisation strand of the Research Support Libraries Programme (RSLP) identified a need to describe resources at a collection level. An entity-relationship model for collections, created by Michael Heaney, was used as the theoretical basis for a metadata schema for collection description
Further information on the model is available in the document “An Analytical Model Of Collections And Their Catalogues” by Michael Heaney. This can be accessed at the URL: <http://www.ukoln.ac.uk/metadata/rslp/model/>
Filed under: Collection Description | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This briefing document provides an introduction to Collection Description.
What Is Collection Description?
Collection Description is a term which is used to describe structured information about a group of resources (a collection) that have some identifiable relationship to each other.
Where traditionally collection descriptions have been included in directories and guides of various forms, metadata records are used in today’s digital environment.
Why Use Collection Description?
Collection description can be used for several reasons:
- To provide easier high level navigation of a large resource base.
- To facilitate the selection of the most appropriate collections for item level searching.
- To support effective searching across archive, library and museum domains.
- As a tool for collection management.
Metadata Schema Model
The digitisation strand of the Research Support Libraries Programme (RSLP) identified a need to describe resources at a collection level. An entity-relationship model for collections, created by Michael Heaney, was used as the theoretical basis for a metadata schema for collection description for RSLP.
Further information on the model is available in the document “An Analytical Model Of Collections And Their Catalogues” by Michael Heaney. This can be accessed at the URL: <http://www.ukoln.ac.uk/metadata/rslp/model/>
RSLP Collection Metadata Schema
The key attributes of this metadata schema are:
- Title, description
- Resource type, collection identifier
- Language, physical characteristics, dates collected, dates items created
- Legal status, access control
- Accrual status (method, periodicity, policy)
- Custodial history, collector, owner, administrator, location
- Subject (concept, object, name, place, time)
- Sub-collection, super-collection, catalogue, associated collection, associated publication
- Note
Dublin Core Collections Application Profile
The key attributes of this metadata schema are:
- Title, alternative title, description
- Resource type, collection identifier
- Size, language, item type, item format, dates collected, dates items created
- Rights, access rights
- Accrual method, periodicity, policy
- Custodial history, collector, owner, location
- Audience, subject, place, time
- Sub-collection, super-collection, catalogue, associated collection, associated publication
Further Information
Further information is provided by the Collection Description Focus Web site tutorial which is available at the URI: <http://www.ukoln.ac.uk/cd-focus/cdfocus-tutorial/schemas/>.
Filed under: Collection Description | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Background
Page layout, content and navigation are not always designed at the same time. It is often necessary to work through at least part of these processes separately. As a result, it may not be possible to test layouts with realistic content until a relatively late stage in the design process, meaning that usability problems relating to the layout may not be found at the appropriate time.
Various solutions exist for this problem. One is the possibility of testing early prototype layouts containing ‘greeked’ text – that is, the ‘lorem imsum’ placeholder text commonly used for layout design [1]. A method for testing the recognisability of page elements was discussed in Neilsen’s Alertbox back in 1998 [2], though the concept originated with Thomas S. Tullis [3].
Technique
Testing will require several users – around six is helpful without being excessively time-consuming. Ensure that they have not seen or discussed the layouts before the test! First, create a list of elements that should be visible upon the layout. Nielsen provides a list of nine standard elements that are likely to present on all intranet pages – but in your particular case you may wish to alter this list a little to encompass all of the types of element present on this template.
Give each test user a copy of each page – in random sequence, to eliminate any systematic error that might result from carrying the experience with the first page through to the second. Ask the test user to draw labelled blocks around the parts of the page that correspond to the elements you have identified. Depending on circumstances, you may find that encouraging the user to ‘think aloud’ may provide useful information, but be careful not to ‘lead’ the user to a preferred solution.
Finally, ask the user to give a simple mark out of ten for ‘appeal’. This is not a very scientific measure, but is nonetheless of interest since this allows you to contrast the user’s subjective measure of preference against the data that you have gathered (the number of elements correctly identified). Nielsen points out that the less usable page is often given a higher average mark by the user.
Scoring The Test
With the information provided, draw a simple table:
| Layout |
Correctly Identified Page Elements |
Subjective Appeal |
| 1 |
N% (eg. 65%) |
# (e.g. 5/10) |
| 2 |
M% (eg. 75%) |
# (e.g. 6/10) |
This provides you with a basic score. You will probably also find your notes from think-aloud sessions to be very useful in identifying the causes of common misunderstandings and recommending potential solutions.
When Should Page Template Evaluation Be Carried Out?
This technique can be applied on example designs, so there is no need to create a prototype Web site; interface ideas can be mocked up using graphics software. These mockups can be tested before any actual development takes place. For this reason, the template testing approach can be helpful when commissioning layout template or graphical design work. Most projects will benefit from a user-centred design process, an approach that focuses on supporting every stage of the development process with user-centred activities, so consider building approaches like this one into your development plans where possible.
Conclusions
If a developing design is tested frequently, most usability problems can be found and solved at an early stage. The testing of prototype page layouts is a simple and cheap technique that can help to tease out problems with page layout and visual elements. Testing early and often can save money by finding these problems when they are still cheap and simple to solve.
It is useful to make use of various methods of usability testing during an iterative design and development cycle, since the various techniques often reveal different sets of usability problems – testing a greeked page template allows us to separate the usability of the layout itself and the usability of the content that will be placed within this content [2]. It is also important to evaluate issues such as content, navigation mechanisms and page functionality, by means such as heuristic evaluation and the cognitive walkthrough – see QA Focus documents on these subjects [4] [5]. Note that greeked template testing does look at several usability heuristics: Aesthetic & minimalist design and Consistency and standards are important factors in creating a layout that scores highly on this test.
Finally, running tests like this one can help you gain a detailed understanding of user reactions to the interface that you are designing or developing.
References
- Lorem Ipsum Generator,
<http://lorem-ipsum.perbang.dk/>
- Testing Greeked Page Templates, Jakob Nielsen,
<http://www.useit.com/alertbox/980517.html>
- A method for evaluating Web page design concepts, T.S. Tullis. In ACM Conference on Computer-Human Interaction CHI 98 Summary (Los Angeles, CA, 18-23 April 1998), pp. 323-324.
- Introduction To Cognitive Walkthroughs, QA Focus briefing document no. 87,
<http://www.ukoln.ac.uk/qa-focus/documents/briefings/briefing-87/>
- Heuristic Evaluation, QA Focus briefing document no. 89,
<http://www.ukoln.ac.uk/qa-focus/documents/briefings/briefing-89/>
Further Information
Filed under: Needs-checking, Usability | No Comments »
Posted on August 26th, 2010 by Brian Kelly
AJAX and Usability
Although, as described in [1] AJAX can enhance the usability of Web-based services developers need to be aware of various usability problems which may be encountered.
Challenges For AJAX Developers
Concept of State
Once a Web page has been downloaded it has traditionally remained static. AJAX uses dynamic Web page updates which means that state transition (the move from one page view to another) is more complex, as separate elements may update asynchronously. AJAX applications frequently do not store application state information; this breaks the ‘back’ button functionality of the browser. Many Web users use the back button as their primary means of navigation and struggle to control the system without it.
AJAX requires developers to explicitly support this functionality in their software, or use a framework that supports it natively. Various solutions to this problem have been proposed or implemented, such as the use of invisible IFRAME elements that invoke changes which populate the history originally used by the browser’s back button.
A related issue is that as AJAX allows asynchronous data exchange with the server, it is difficult for users to bookmark a particular state of the application. Solutions to this problem are appearing. Some developers use the URL anchor or fragment identifier to keep track of state and therefore allow users to return to the application in a given state.
The asynchronous nature of AJAX can also confound search engines which traditionally record only a page’s static content. Since these usually disregard JavaScript entirely, an alternative access must be provided if it is desirable for a Web page to be indexed.
User Expectations
There are certain expectations of how Web-based information will be displayed and processed. Without explicit visual clues to the contrary, users are unlikely to realise that the content of a page is being modified dynamically. AJAX applications often do not offer visual clues if, for example, a change is being made to the page or content is being preloaded. The usual clues (such as the loading icon) are not always available. Solving this requires designers to explicitly support this functionality, using traditional user interface conventions wherever possible or alternative clues where necessary.
Response Time
AJAX has the potential to reduce traffic between the browser and the server as information can be sent or requested as and when required. However, this ability can easily be misused, such as by polling the server for updates excessively frequently. Since data transfer is asynchronous, a lack of bandwidth need not be perceivable to the user; however, ensuring this is the case requires smart preloading of data.
Design Issues
AJAX provides techniques that previously were available only by using DHTML or a technology like Flash. There is a concern that, as with previous technologies, designers have access to a plethora of techniques that bring unfamiliar usability or accessibility problems. Gratuitous animation, pop ups, blinking text and other distractions all have accessibility implications and stop the user from fully focussing on the task at hand.
Accessibility
Most methods of AJAX implementation rely heavily on features only present in desktop graphical browsers and not in text-only readers. Developers using AJAX technologies in Web applications will find attempting to adhere to WAI accessibility guidelines a challenge. They will need to make sure that alternate options for users on other platforms, or with older browsers and slow Internet connections, are available.
Conclusions
The concerns surrounding adoption of AJAX are not unfamiliar. Like Flash, the technologies comprising AJAX may be used in many different ways; some are more prone to usability or accessibility issues than others. The establishment of standard frameworks, and the increasing standardisation of the technologies behind AJAX, is likely to improve the situation for the Web developer.
In the meantime, the key for developers is to remember is that despite the availability of new approaches, good design remains essential and Jacob Nielson’s Ten Usability Heuristics [2] should be kept in mind. AJAX applications need to be tested to deal with the idiosyncrasies of different browsers, platforms and usability issues and applications should degrade gracefully for those users who do not have JavaScript enabled.
Note that as the use of AJAX increases and more programming libraries become available, many of the issues will be resolved. In parallel it is likely that over time browsers will standardise and incorporate better support for new technologies.
References
- An Introduction To AJAX, Cultural Heritage briefing document no. 43, UKOLN,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-43/>
- Ten Usability Heuristics), Useit.com,
<http://www.useit.com/papers/heuristic/heuristic_list.html>
Filed under: Usability | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Background
When designing a Web site or program, the obvious question to ask at once is, “who are my audience?” It seems natural to design with users in mind, and just as natural to wish to build a product that is satisfactory to all one’s users – however, experience shows that it is difficult to design something that appeals to everybody [1]. Instead, it is useful to start with a few sample profiles of users, typical examples of the audience to whom the design should appeal, and design to their needs. Not only is it easier for the designer, but the result is usually more appealing to the user community.
Researching A User Persona
The first step in developing a user persona is to learn a little about your users; qualitative research techniques like one-to-one interviews are a good place to start. It’s best to talk to several types of users; don’t just focus on the single demographic you’re expecting to appeal to, but consider other groups as well. Focusing on one demographic to the exclusion of others may mean that others do not feel comfortable with the resulting design, perhaps feeling alienated or confused. The expected result of each interview is a list of behaviour, experience and skills. After a few interviews, you should see some trends emerging; once you feel confident with those, it’s time to stop interviewing and start to build personas.
Developing A User Persona
Once you have an idea of each type of persona, write down the details for each one. It may help to write a sort of biography, including the following information:
- Vital statistics: name, age, gender and personality details (shy, timid, outgoing?)
- Interests and hobbies
- Experience and education
- Motivation
You can even find a photograph or sketch that you feel fits the personality and add it to the persona’s description.
Why User Personas?
The intent behind a user persona is to create a shared vocabulary for yourself and your team when discussing design questions and decisions. User personas provide easy-to-remember shorthand for user types and behaviour, and can be used to refer to some complex issues in a simple and generally understood way. Sharing them between management and development teams, perhaps even with funders, also provides a useful avenue for effective communication of technical subjects. Furthermore, it is much easier to design for a persona with whom one can empathise than for a brief, dry description of user demographics.
It is good practice, when making design decisions, to consider each user persona’s likely reaction to the result of the decision. Which option would each user persona prefer?
User personas can also feed in to discount usability testing methods such as the cognitive walkthrough, saving time and increasing the effectiveness of the approach.
Finally, the research required to create a user persona is an important first step in beginning a user-centred design process, an approach that focuses on supporting every stage of the development process with user-centred activities, which is strongly recommended in designing for a diverse user group.
Conclusions
User personas are a useful resource with which to begin a design process, which allow the designers to gain understanding of their users’ expectations and needs in a cheap and simple manner, and can be useful when conducting discount usability testing methods. Additionally, they make helpful conversational tools when discussing design decisions.
References
- The Inmates are Running the Asylum, Alan Cooper, ISBN: 0672316498
Further Information
Filed under: Needs-checking, Usability | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Background
Heuristic evaluation is a method of user testing, which enables a product to be assessed in order to identify usability problems – that is, places where the product is not easy to use. It is a discount (“quick and dirty”) method, which means that it is cheap and requires relatively little expertise.
What’s Involved In Heuristic Evaluation?
In this technique, a number of evaluators are first introduced to the heuristics, then given some tasks to complete and invited to report the problems – where the system fails to comply with the heuristics – either verbally or in some form of written report or checklist. Unlike many forms of usability testing, the evaluators do not have to be representative of the system’s expected users (although they can be!), nor do the evaluators have to be experts, as the heuristics can be read and understood in a few minutes. Just three to five evaluators are needed to find the majority of usability problems, so the technique is quite efficient and inexpensive.
The problems found in heuristic evaluation essentially represent subjective opinions about the system. Evaluators will frequently disagree (there are no absolute right or wrong answers) but these opinions are useful input to be considered in interface design.
What Heuristics Should I Use?
There are several sets of possible heuristics available on the Web and elsewhere. This reflects the fact that they are “rules of thumb”, designed to pick out as many flaws as possible, and various sets of usability evaluators have found different formalisations to be most useful for their needs, e.g. [1]. Probably the most commonly used is Nielsen’s set of ten usability heuristics [2] given below with a sample question after each one:
- Visibility of system status: Does the system give timely & appropriate feedback?
- Match between system and the real world: Is it speaking the users’ language?
- User control and freedom: How hard is it to undo unwanted actions?
- Consistency and standards: Does it follow conventions and expectations?
- Error prevention: Are potential errors recognised before becoming a problem?
- Recognition rather than recall: Does the system rely on the users’ memory?
- Aesthetic & minimalist design: Are dialogs cluttered with information?
- Help users recognise, diagnose & recover from errors: Are error messages useful?
- Help and documentation: Is there online help? Is it useful?
An excellent resource to help you choose a set of heuristics is the Interactive Heuristic Evaluation Toolkit [3] which offers heuristics tailored to your expected user group, type of device, and class of application.
When Should Heuristic Evaluation Be Carried Out?
As heuristic evaluation is simple and cheap, it is possible to use it to quickly test the usability of a web site at any stage in its development. Waiting until a fully functional prototype Web site exists is not necessary; interface ideas can be sketched out onto paper or mocked up using graphics software or Flash. These mockups can be tested before any actual development takes place.
Most projects will benefit from a user-centred design process, an approach that focuses on supporting every stage of the development process with user-centred activities. It is advisable to test early and often, in order to ensure that potential problems with a design are caught early enough that they can be solved cheaply. However, even web sites that are already active can benefit from usability testing, since many such problems are easily solved, but some problems are difficult or expensive to solve at a late stage.
Conclusions
If a developing design is tested frequently, most usability problems can be found and solved at an early stage. Heuristic evaluation is a simple and cheap technique that finds the majority of usability problems. An existing Web site or application will often benefit from usability testing, but testing early and often provides the best results. Finally, it is useful to alternate use of heuristic evaluation with use of other methods of usability testing, such as user testing, since the two techniques often reveal different sets of usability problems.
References
- Heuristic Evaluation – A System Checklist, Deniese Pierotti, Xerox Corp.
<http://www.stcsig.org/usability/topics/articles/he-checklist.html>
- Heuristic Evaluation, Jakob Nielsen,
<http://www.useit.com/papers/heuristic/>
- Interactive Heuristic Evaluation Toolkit,
<http://www.id-book.com/catherb/>
Further Information
Filed under: Usability | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Background
A key issue in usability is that of understanding users, and a key part of user-centred design is that of describing the tasks that the users expect to be able to accomplish using the software you design [1]. Because of the origins of usability as a discipline, a lot of the terminology used when discussing this issue comes from fields such as task analysis. This briefing paper defines some of these terms and explains the relationship between usability and task analysis.
What Is Task Analysis?
Within the usability and human-computer interaction communities, the term is generally used to describe study of the way people perform tasks – that is, the way in which a task is currently performed in real-life situations. Task analysis does not describe the optimal or ideal procedure for solving a problem. It simply describes the way in which the problem is currently solved.
Gathering Data For Task Analysis
Since the intent of task analysis is description of an existing system, the ideal starting point is data gathered from direct observation. In some cases, this is carried out in a controlled situation such as a usability laboratory. In others, it is more appropriate to carry out the observation “in the field” – in a real-life context. These may yield very different results!
Observational data can be gathered on the basis of set exercises, combined with the “think-aloud” technique, in which subjects are asked to describe their actions and their reasoning as they work through the exercise. Alternatively, observations can be taken by simply observing subjects in the workplace as they go through a usual day’s activities. The advantage of this latter method is principally that the observer influences events as little as possible, but the corresponding disadvantage is that the observations are likely to take longer to conclude.
Unfortunately, there are significant drawbacks of direct observation, principally cost and time constraints. For this reason, task analysis is sometimes carried out using secondary sources such as manuals and guidebooks. This, too, has drawbacks – such sources often provide an idealised or unrealistic description of the task.
A third possibility is conducting interviews – experts, themselves very familiar with a task, can easily answer questions about that task. While this can be a useful way of solving unanswered questions quickly, experts are not always capable of precisely explaining their own actions as they can be too familiar with the problem domain, meaning that they are not aware on a conscious level of the steps involved in the task.
Analysing Observations
There are several methods of analysing observational data, such as knowledge-based analysis, procedural [2] or hierarchical task analysis, goal decomposition (the separation of each goal, or step, into its component elements) and entity-relationship based analysis. Data can also be visualised by charting or display as a network. Some methods are better suited to certain types of task – e.g. highly parallel tasks are difficult to describe using hierarchical task analysis (HTA). On the other hand, this method is easy for non-experts to learn and use. Each answers a slightly different question – for example, HTA describes the knowledge and abilities required to complete a task, while procedural task analysis describes the steps required to complete a task.
A simple procedural task analysis is completed as follows:
- Choose the appropriate procedure to complete the task that is being analysed.
- Determine and write down each step in that procedure; break down each step as far as possible.
- Complete every step of the procedure.
- Check that the procedure gave the correct result.
These steps can be charted as a flowchart for a clear and easy to read visual representation.
Conclusions
Task analysis provides a helpful toolkit for understanding everyday processes and for describing how human beings solve problems. It is not appropriate to perform detailed task analysis in every situation, due to cost and complexity concerns. However, the results of a task analysis can usefully inform design or pinpoint usability problems, particularly differences between the system designer’s assumptions and the users’ “mental models” – ways of looking at – the task to be performed.
References
- Task Analysis and Human-Computer Interaction, Crystal & Ellington,
<http://www.ils.unc.edu/~acrystal/AMCIS04_crystal_ellington_final.pdf>
- Procedural Task Analysis,
<http://classweb.gmu.edu/ndabbagh/Resources/Resources2/procedural_analysis.htm>
Filed under: Needs-checking, Usability | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Introduction To Cognitive Walkthroughs
The cognitive walkthrough is a method of discount (“quick and dirty”) usability testing requiring several expert evaluators. A set of appropriate or characteristic tasks to be completed is compiled. The evaluators then “walk” through each task, noting down problems or difficulties as they go.
Since cognitive walkthroughs are often applied very early in development, the evaluators will often be working with mockups of interfaces such as paper prototypes and role-playing the part of a typical user. This is made much simpler if user personas, detailed descriptions of fictitious users, have been developed, because these simplify the role-playing element of cognitive walkthrough. These are often developed at the beginning of a user-centred design process, because designers often find it much easier to design to the needs of a specific user.
Evaluators are typically experts such as usability specialists, but the same basic technique can also be applied successfully in many different situations.
The Method
Once you have a relatively detailed prototype, paper or otherwise, you are ready to try a cognitive walkthrough.
Start off by listing the tasks that you expect users to be able to perform using your Web site or program. To do this, think about the possible uses of the site; perhaps you are expecting users to be able to book rooms or organise tours, or find out what events your organisation is running in the next month, or find opening times and contact details for your organisation. Write down each of these tasks.
Secondly, separate these tasks into two parts: the user’s purpose (their intention) and the goals that they must achieve in order to complete this. Take the example of organising a tour; the user begins with the purpose of finding out what tours are available. In order to achieve this, they look for a link on your Web site leading to a Web page detailing possible tours. Having chosen a tour, they gain a new purpose – organising a tour date – and a new set of goals, such as finding a Web page that lets them book a tour date and filling it out appropriately.
Separating tasks into tiny steps in this way is known as decomposition, and it is mostly helpful because it allows you to see exactly where and when the interface fails to work with the user’s expectations. It is important to do this in advance, because otherwise you find yourself evaluating your own trial-and-error exploration of the interface! Following these steps “wearing the users’ shoes” by trying out each step on a prototype version of the interface shows you where the user might reach an impasse or a roadblock and have to retrace his or her steps to get back on track. As a result, you will gain a good idea of places where the interface could be made simpler or organised in a more appropriate manner.
To help this process, a Walkthrough Evaluation Sheet is filled in for each step taken. An example is shown below [1]:
- Will the users be trying to produce whatever effect the action has?
- Will users see the control (button, menu, switch, etc.) for the action?
- Once users find the control, will they recognize that it produces the effect they want?
- After the action is taken, will users understand the feedback they get, so they can go on to the next action with confidence?
Advantages and Disadvantages
Cognitive walkthroughs are often very good at identifying certain classes of problems with a Web site, especially showing how easy or difficult a system is to learn or explore effectively – how difficult it will be to start using that system without reading the documentation, and how many false moves will be made in the meantime.
The downside is principally that on larger or more complex tasks they can sometimes be time-consuming to perform, so the technique is often used in some altered form. For example, instead of filling out an evaluation sheet at each step, the evaluation can be recorded on video [2]; the evaluator can then verbally explain the actions at each step.
Conclusions
‘Cognitive walkthroughs are helpful in picking out interface problems at an early stage, and works particularly well together with a user-centred design approach and the development of user personas. However, the approach can sometimes be time-consuming, and since reorganising the interface is often expensive and difficult at later stages in development, the cognitive walkthrough is usually applied early in development.
References
- Evaluating the design without users, from Task-Centered User Interface Design,
<http://hcibib.org/tcuid/chap-4.html>
- The Cognitive Jogthrough,
<http://portal.acm.org/citation.cfm?id=142869>
Filed under: Usability | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Background
Usability refers to a quality attribute that assesses how easy user interfaces are to use. The term is also used to refer to a number of techniques and methods for improving usability during the various stages of design and development.
What Does Usability Include?
Usability can be separated into several components [1] such as:
- Learnability:
- How easy it is to get to grips with an unfamiliar interface?
- Efficiency:
- How quickly an experienced user can perform a given task?
- Memorability:
- Once familiar with an interface, is it easily forgettable?
- Errors:
- How easy is it to make mistakes/recover from mistakes?
- Satisfaction:
- Is the design enjoyable to use?
These characteristics are all useful metrics, although the importance of each one depends on the expected uses of the interface in question. In some circumstances, such as software designed for a telephone switchboard operator, the time it takes for a skilled user to complete a task is rather more important than learnability or satisfaction. For an occasional web user, a web site’s designers may wish to focus principally on providing a site that is learnable, supports the user, and is enjoyable to use. Designing a usable site therefore requires a designer to learn about the needs of the site’s intended users, and to test that their design meets the criteria mentioned above.
Why Does Usability Matter?
More attention is paid to accessibility than to usability in legislation, perhaps because accessibility is perceived as a clearly defined set of guidelines, whilst usability itself is a large and rather nebulous set of ideas and techniques. However, a Web site can easily pass accessibility certification, and yet have low usability; accessibility is to usability what legible handwriting is to authorship. Interfaces with low usability are often frustrating, causing mistakes to be made, time to be wasted, and perhaps impede the user from successfully reaching their intended goal at all. Web sites with low usability will not attract or retain a large audience, since if a site is perceived as too difficult to use, visitors will simply prefer to take their business elsewhere.
Usability Testing
User testing is traditionally an expensive and complicated business. Fortunately, modern discount (‘quick and dirty’) methods have changed this, so that it is now possible to quickly test the usability of a web site at any stage in its development. This process, of designing with the user in mind at all times, is known as user-centred design. At the earliest stages, an interface may be tested using paper prototypes or simple mockups of the design. It is advisable to test early and often, to ensure that potential problems with a design are caught early enough to solve cheaply and easily. However, completed Web sites also benefit from usability testing, since many such problems are easily solved.
User testing can be as simple as asking a group of users, chosen as representative of the expected user demographic, to perform several representative tasks using the Web site. This often reveals domain-specific problems, such as vocabulary or language that is not commonly used by that group of users. Sometimes user testing can be difficult or expensive, so discount techniques such as heuristic evaluation [2], where evaluators compare the interface with a list of recommended rules of thumb, may be used. Other discount techniques include cognitive walkthrough in which an evaluator role-plays the part of a user trying to complete a task. These techniques may be applied to functional interfaces, to paper prototypes, or other mockups of the interface.
A common method to help designers is the development of user personas, written profiles of fictitious individuals who are designed to be representative of the site’s intended users. These individuals’ requirements are then used to inform the design process and to guide the design process.
Conclusions
Considering the usability of a web site not only helps users, but also tends to improve the popularity of the site in general. Visitors are likely to get a better impression from usable sites. Quick and simple techniques such as heuristic evaluation can be used to find usability problems; frequent testing of a developing design is ideal, since problems can be found and solved early on. Several methods of usability testing can be used to expose different types of usability problems.
References And Further Information
- Usability 101: Introduction to Usability, J. Nielsen,
<http://hcibib.org/tcuid/chap-4.html>
- Heuristic Evaluation, J. Nielsen,
<http://portal.acm.org/citation.cfm?id=142869>
Filed under: Needs-checking, Usability | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Why The Interest In Facebook?
Facebook has generated much interest over recent months. Much of the interest has arisen since Facebook announced the Facebook Platform [1] which enabled third party developers to build applications which could be used within the Facebook environment.
Since Facebook was developed initially to support students it is not surprising that student usage has proved so popular. This interest has also spread to other sectors within institutions, with researchers and members of staff exploring Facebook possibilities.
What Can Be Done Within Facebook?
Social networks can provide a range of benefits to members of an organisation:
- Connections with peers
- The main function of Facebook is to provide connections between people with similar interests. Friends can then send messages to each other (either closed messages or open for others to read).
- Groups
- Facebook users can set up discussion group areas, which can be used by people with interests in the topic of the group. Creation of details of events, which allows users to sign up to, is another popular use of Facebook.
- Sharing resources
- Many of the popular Facebook applications are used for sharing resources. Some of these replicate (or provide an interface to) popular social sharing services (such as Flickr and YouTube) while other applications provide services such as sharing interests in films, books, etc.
- An environment for other applications
- he opening of the Facebook Platform has allowed developers to provide access to a range of applications. The ArtShare application [2], for example, provides access to arts resources from within Facebook.
- Web presence
- Although originally designed for use by individuals since November 2007 Facebook can be used as a Web hosting service for organisational pages.
It should also be noted that organisational pages in Facebook were redesigned in 2009 so that they more closely resemble personal pages [3]. Organisational pages are now also able to share status updates.
What Are The Challenges?
Reservations about use of Facebook in an institutional context include:
- Privacy
- There are real concerns related to users’ privacy. This will include both short term issues (embarrassing photos being uploaded) and longer term issues (reuse of content in many years time).
- Ownership
- The Facebook terms and conditions allow Facebook to exploit content for commercial purposes.
- Misuse of social space
- Users may not wish to share their social space with other colleagues, especially when there may be hierarchical relationships.
- Liability
- Who will be liable if illegal content or copyrighted materials are uploaded to Facebook? Who is liable if the service is not accessible to users with disabilities?
- Sustainability and Interoperability
- How sustainable is the service? Can it provide mission-critical services? Can data be exported for reuse in other systems?
- Resources
- The cost implications in developing services for the Facebook platform.
Institutional Responses To Such Challenges
How should institutions respond to the potential opportunities provided by Facebook and the challenges which its use may entail? The two extreme positions would be to either embrace Facebook, encouraging its use by members of the institution and porting services to the environment or to ban its use, possibly by blocking access by the institutions firewall. A more sensible approach might be to develop policies based on:
- Risk assessment and risk management
- Analysing potential dangers and making plans for such contingencies. Note that the risk assessment should also include the risks of doing nothing
- User education
- Developing information literacy / staff development plans to ensure users are aware of the implications of use of Facebook, and the techniques for managing the environment (e.g. privacy settings).
- Data management
- Developing mechanisms for managing data associated with Facebook. This might include use of Facebook applications which provide alternative interfaces for data import/export, exploring harvesting tools or engaging in negotiations with the Facebook owners.
References
- Major Facebook Announcement Thursday: Facebook Platform, Mashable, 21 May 2007,
<http://mashable.com/2007/05/21/facebook-f8/>
- Artshare, Brooklyn Museum Blog, 8 Nov 2007,
<http://www.brooklynmuseum.org/community/blogosphere/bloggers/2007/11/08/artshare-on-facebook/ >
- 3. New Facebook Pages: A Guide for Social Media Marketers, Mashable blog, 3 Mar 2009,
<http://mashable.com/2009/03/04/new-facebook-pages/>
Filed under: Needs-checking, Social Networks | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This document gives advice on addressing possible barriers you might face when setting up a blog in a cultural heritage context.
Piloting Your Blogging Service
Libraries will often trial a service to test the product and to gauge the response of their library users. Developing your blog as a ‘pilot’ project provides a low-risk, comfortable environment to experiment with the service, and gather feedback from your library community. Setting up the service as a trial allows bloggers and their managers or colleagues to see exactly how much time or resource support is required. It also provides an exit or withdrawal strategy if needed.
Small-scale Activities
Experiment with blogs by supporting a small-scale activity, such as a special event or occasion. This negates the need for ongoing support or commitment, but it gives a taste of the strengths and opportunities of blogs.
A blog for an internal working party or committee is another way to introduce blogs. Inviting library staff to join a closed membership blog gives the opportunity to experiment with the blog and add posts and comments without it being exposed to the general public.
Policies To Soothe Institutional Concerns
Many organisations are reluctant to release material to their library users until it has been vetted by a publications group or similar process. This may be presented as a barrier to establishing a blogging service. To counter this argument, it may be wise to develop a robust set of policies outlining the quality processes to which the blog style and content will be subjected (see briefing paper no. 5 on Developing Blog Policies [1]).
Include a statement in your blog policies to welcome feedback and notification of errors, and that any identified problems will be addressed as quickly as possible. A fundamental advantage of blogs is that they allow for immediate alterations or changes.
Low Cost, Minimal Resources
Many conventional communications have associated costs (paper, laminating, etc) but setting up a blog can be a low cost solution. Popular blogging sites like WordPress, Typepad, LiveJournal and Blogger allow for template modification to match organisational themes for no outlay. Little knowledge of HTML or design principles is needed to create a professional-looking blog.
Demystifying Blogs With Best Practice Examples
Your library colleagues have likely come across negative as well as positive coverage of blogs and blogging in the press. Blogs have been described as vanity publishing and as a platform on which anyone can relate excruciatingly detailed minutiae of their lives.
Responsible blogging offers the opportunity to engage with your library users using a format with which they are familiar. There are many great library related blogs available and it may help to build these into a collection for circulation amongst your colleagues. Look at the blogrolls on your favourite blogs for new leads or keep an eye on your library association literature for pointers to new blogs displaying best practices.
Participating On Other Blogs
It will help to advocate for a blogging service if you are familiar with blog processes and have actively engaged or participated in blogging. Build your confidence by participating in group blogs, or set up a blog outside of work. If you are part of a society or organisation, start a blog to highlight the group’s events or activities. Use a blog to record your professional development, such as library association chartership.
Demonstrating Value
Hosted blog services all contain built-in statistical reporting, providing information on number of views and popular posts. It may be useful to read the ‘Evaluating your Blog‘ Briefing Paper [2] for more information on demonstrating the value of a blog.
Encouraging Enthusiasts
Seek out blog ‘champions’ or colleagues who are supportive of blogging activities. One approach for creating interest may be to add a ‘Learn to blog’ session to your staff development activities. Invite colleagues (or better yet – users!) who are blog enthusiasts to share their activities.
References
- 1. Developing Blog Policies, Cultural heritage briefing document no. 5, UKOLN,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-5/>
- Evaluating Your Blog, Cultural heritage briefing document no. 10, UKOLN,
<http://www.ukoln.ac.uk/cultural-heritage/documents/briefing-10/>
Filed under: Blogs, Needs-checking | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This document provides advice on a variety of technical issues which need to be addressed when you are planning your blog service.
Externally Hosted Or Locally Hosted Software?
Where should you host your blog software? Traditionally when organisations have wished to provides IT services they have either installed software in-house, or negotiated a contract with an external provider. However many Web 2.0 services, including blogs, can be used for free by external blog providers such as WordPress or Blogger.
What are the pros and cons of making use of a 3rd party service?
- Advantages
- Little technical expertise needed. No negotiations with an IT Services department needed. You can select your preferred providers based on your requirements, rather than needing to comply with locally approved solutions. You may have more flexibility and be able to experiment with a service provided by a third party.
- Disadvantages
- There may be risks related to the long term availability of a third-party service. You may not be able to be guaranteed desired levels of service. There may be legal issues, such as data protection, privacy, accessibility, etc. which could be unresolved. You will not receive the level of support you would receive from an in-house supported product.
Note that a briefing document on “Risk Assessment For Use Of Third Party Web 2.0 Services” [1] provides further information on the risks of using externally-hosted services.
Selection Of The Software
It may be useful to make the choice of the architecture (in-house or external) and the particular blog software by considering the choices made by similar organisations to yours. Discussions on mailing lists (e.g. the lis-bloggers mailing list [2] may be helpful.
Blog Configuration Options
Once you have selected your blog software and either installed it or set up an account, you will then have to make various decisions about how the blog is configured. This will include:
- Appearance of the blog
- You will normally be able to select a ‘theme’ for your blog, from a number of options, which may cover the number of columns, use of sidebars for additional content, etc. You may also wish to brand your blog with logos, organisational colour scheme, etc. Note, though, that configuration options may not be available (or may cost) with third-party blog services.
- Additional Content
 You may wish to provide additional content on your blog. This might include additional pages or content in the blog’s sidebar, such as a ‘blogroll’ of links to related blogs or blog ‘widgets’. An example of the administrator’s interface for blog widgets on the UK Web Focus blog is shown.
You may wish to provide additional content on your blog. This might include additional pages or content in the blog’s sidebar, such as a ‘blogroll’ of links to related blogs or blog ‘widgets’. An example of the administrator’s interface for blog widgets on the UK Web Focus blog is shown.- Tags
- You may wish to chose the ‘categories’ (or tags) to be associated with your posts. This will allow readers to easily access related posts. You may wish to select categories prior to the launch of your blog; you will be able to add new categories at a later date.
- Policy on User Comments
- You will need to establish a policy of whether you allow your readers to give comments on blog posts and, if you do, whether such comments need to be moderated before being appended to a blog post.
- Options for Blog Authors
- You may need to set up various options for contributors to this blog. This might include use of spell checkers, conventions for how dates are displayed, email addresses of the contributors, etc.
Managing Accounts
If you have chosen to have a team blog, you will need to set up accounts for the contributors to the blog.
References
- Risk Assessment For Use Of Third Party Web 2.0 Services, QA Focus briefing document no. 98, UKOLN,
<http://www.ukoln.ac.uk/qa-focus/documents/briefings/briefing-98/>
- lis-bloggers, JISCMail,
<http://www.jiscmail.ac.uk/lists/LIS-BLOGGERS.html>
Filed under: Blogs, Needs-checking | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This document provides advice on approaches you can take to evaluating the effectiveness of your blog.
The Role Of Your Blog
In order to evaluate the effectiveness of your blog, you should have a clear idea of its purpose (although you may find that the purpose evolves over time). Possible uses of a blog service include acting as a dissemination channel for an organisation, engaging the user community in discussion and debate acting as a gateway to other resources, or perhaps more speculative purposes, such as experimentation or ‘thinking out loud’.
Policies For Your Blog
It may be advantageous to provide documented policies for your blog, which might include details of the purpose(s) of your blog, the scope and target audience and possibly details of quality assurance processes you will use to ensure the blog implements its purposes successfully.
The UK Web Focus blog has published its policy statement [1], which includes details of its purposes (dissemination, user engagement, providing information on and commentary on new Web technologies, experimentation with blog tools and speculative thinking), scope (Web and related issues) and target audiences (Web development community, especially in the UK education and cultural heritage sectors).
Feedback For Your Blog Posts
If your blog aims to provide two-way communications, you should allow comments to be made for individual posts. One policy decision you will have to make is whether to allow unmoderated comments to be made. This can provide a more interactive service, but there may be risks in allowing inappropriate posts to be published.
User comments on individual posts will help you to gain feedback on the content of the posts. In order to encourage your blog readers to post their comments, you should seek to provide speedy responses to comments which are made.
Evaluating Blog Usage
If only small numbers of people read your blog, then it may fail to fulfil its purpose (if the purposes are dissemination and user engagement; for blogs used for other purposes, such as reflective thinking, such usage statistics may not be relevant). Systematic monitoring of your blog site’s usage statistics can therefore be helpful in identifying the effectiveness and potential impact of your blog service.
 The diagram shows growth in visits to the UK Web Focus blog since its launch in November 2006, with a steady increase in numbers (until August 2007 when many readers were away).
The diagram shows growth in visits to the UK Web Focus blog since its launch in November 2006, with a steady increase in numbers (until August 2007 when many readers were away).
Note that if your blog readers make significant use of RSS readers or your blog is aggregated in other locations, your blog site’s usage statistics may under-report the numbers of readers.
What Are They Saying About You?
It can be useful to explore the links users follow when they read your posts. Such information may be provided on your blog service. For example the image shows a number of the referrer links to recent posts on the UK Web Focus blog. In this case, two links are from blogs which commented on a post about a Web service called VCasmo. The comments give an indication of the blog’s effectiveness and impact.
As can be seen in their use with the UK Web Focus blog, blog search engines such as Technorati [2] and Google Blog search [3] can help find posts which link to your blog.
Systematic Evaluation
It may prove useful to carry out an online evaluation of your blog, as was done towards the end of the first year of the UK Web Focus blog [4].
References
- Blog Policies, UK Web Focus blog,
<http://ukwebfocus.wordpress.com/blog-policies/>
- Blog Reactions, Technorati,
<http://technorati.com/blogs/ukwebfocus.wordpress.com/?reactions>
- Google Blog Search, Google,
<http://blogsearch.google.com/blogsearch?q=link:http://ukwebfocus.wordpress.com/>
- Your Feedback On The UK Web Focus Blog, UK Web Focus blog, 23 Aug 2007,
<http://ukwebfocus.wordpress.com/2007/08/23/your-feedback-on-the-uk-web-focus-blog/>
Filed under: Blogs | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Background
The briefing document provides suggestions on approaches you can take to building a blogging community, including a community of authors and a community of peers.
The Potential Benefits Of A Blogging Community
Blogging is often perceived of as an individual activity. However successful blogs are likely to involve community building, whether this is a community of co-authors, a community of readers or a community of peers.
Team Blogging
The responsibilities of producing regular blog posts over an extended period may be onerous. A solution to this would be to provide a team blog, in which the task of identifying topics of interest, writing the post and responding to comments can be shared. The Archive Hub blog provides an example of this type of approach [1]
It should be noted, though, that a team approach can dilute the ‘voice’ of a blog, and may not be applicable in all cases.
Guest Blog Posts
Another approach to sharing responsibilities for writing posts may be to encourage occasional guest blog posts. This approach has been taken on the UK Web Focus blog [2]. Advantages of guest blog posts include adding variety and a different voice to your blog, providing a forum for others and engaging with new communities.
Blog Widgets To Support Community-Building
Blog widgets enable additional functionality to be provided on your blog. A wide range of blog widgets are available which cover a range of functions. Of relevance to this document are widgets which can support community building. Widgets such as Meebo [3] and TokBox [4] provide realtime text chat and video conferencing facilities for your blog which can help to provide more interactive and engaging services for your blog readers.
Engaging With Your Peers

Another approach to community-building is sharing experiences and best practices with one’s peers, such as fellow bloggers who work in the same sector.
In the information sector this could include participating in mailing lists aimed at the blogging community (such as the lis-bloggers JISCMail list [5]) or participating in social networking services, such as the Library 2.0 Ning group [6] or the Library 2.0 Interest Group Facebook group [7].
Staff Development
An important aspect in the provision of quality blogging services is professional development for those involved in the provision of blog services. Fortunately there are a range of online services available which can be used to improve one’s blogging skills. As well as blogs provided by experienced information professionals [8] and [9] there are online blogging courses, such as the 31 Days project [10].
References
- Archives Hub Blog, Archives Hub,
<http://www.archiveshub.ac.uk/blog/>
- Guest Blog Posts, UK Web Focus Blog,
<http://ukwebfocus.wordpress.com/tag/blog/guest-post/>
- Meebo – A Follow-Up, UK Web Focus Blog, 26 Jan 2007,
<http://ukwebfocus.wordpress.com/2007/01/26/meebo-a-follow-up/>
- TokBox – A Useful Video-Conferencing Tool Or Something Sinister?, UK Web Focus Blog, 19 Sep 2007,
<http://ukwebfocus.wordpress.com/2007/09/19/tokbox-a-useful-video-conferencing-tool-or-something-sinister/>
- lis-bloggers, JISC Mail,
<http://www.jiscmail.ac.uk/lists/LIS-BLOGGERS.html>
- Library 2.0, Ning,
<http://library20.ning.com/>
- Library 2.0 Interest Group, Facebook,
<http://bathac.facebook.com/group.php?gid=2212848798>
- Phil Bradley’s Blog,
<http://www.philbradley.typepad.com/>
- Tame The Web blog, Michael Stephens,
<http://tametheweb.com/>
- 31 Days to a Building Better Blog Challenge, The Bamboo Project,
<http://michelemartin.typepad.com/thebambooprojectblog/join-the-31-days-to-build.html>
Filed under: Blogs | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
This document provides advice on steps you may wish to take once you are in the process of launching a blog.
Claiming Your Blog In Technorati
Technorati is the best known search engine for blogs. If you wish to make the contents in your blog easily found by others you are advised to ‘claim your blog’ in Technorati.
This process involves first registering with Technorati [1] and then providing the address of your blog to Technorati [2] and keywords which are relevant for your blog. This enables Technorati to automatically index new posts, shortly after they have been published. Please note that, in order to stop others from claiming your blog (which would enable them to view statistics for your blog) you will need to temporarily embed some special code in your blog in order to establish that you own the blog).
Accessing Technorati Information About Your Blog
Once you have successfully claimed your blog you should find that your blog posts will be indexed by Technorati shortly after they have been published. To check this, simply sign in to the Technorati Web site and you should be able to view further information about your blog, including details of the posts which have been indexed. You can also see details of Technorati users who have added your blog to their list of favourites. You may wish to use Technorati to add blogs you find of interest to your list of favourites.
Viewing Technorati Statistics
You will also find that Technorati provides statistics for the Authority and Ranking for your blog. This is based on the numbers of links there are from other blogs (which Technorati knows about) to your blog over a period of 6 months.
Further information on these statistics is available on the Technorati Web site [3].
Keeping Records
It can be useful to ensure that you keep records related to the usage and impact of your blog from its launch.
Many blog services will provide statistics on the numbers of visitors to the blog Web site, but you may find it useful to complement this with an embedded usage monitoring service such as SiteMeter, used on the UK Web Focus blog [4].
As described on the UK Web Focus blog [5] services such as Blotter can be used to visualise the trends in Technorati ratings, as illustrated. This can be helpful in making it easy to spot sudden jumps or falls in the ratings.
Marketing Your Blog
As well as making use of various Web services which can help users to find your blog, you should also implement a marketing strategy for your blog. Possible approaches to this could include: (a) including details of your blog in your email signature, your business card, etc. (b) providing flyers, posters, etc. about your blog and (c) citing blog posts in other media, such as in responses to email queries, in presentations, etc.
Documented Experience
The experiences gained after launching the UK Web Focus blog in November 2006, including details of ‘claiming’ of the blog and how this helped people to find the blog and how this helped in attracting traffic have been documented in the blog [6] [7].
References
- Member Sign Up, Technorati,
<http://technorati.com/account>
- My Account, Technorati,
<http://technorati.com/account/blogs/>
- What Is Authority?, Technorati,
<http://support.technorati.com/faq/topic/71?replies=1>
- SiteMeter Added To Blog, UK Web Focus blog, 22 Jan 2007,
<http://ukwebfocus.wordpress.com/2007/01/22/sitemeter-added-to-blog/>
- Blogging And Learning From Ones Peers, UK Web Focus blog, 31 May 2007,
<http://ukwebfocus.wordpress.com/2007/05/31/blogging-and-learning-from-ones-peers/>
- I’ve A Blog – What Next?, UK Web Focus blog, 6 Nov 2006,
<http://ukwebfocus.wordpress.com/2006/11/06/ive-a-blog-what-next/>
- Word of Blog – 3 Week’s Later, UK Web Focus blog, 23 Nov 2006
<http://ukwebfocus.wordpress.com/2006/11/26/word-of-blog-3-weeks-later/>
Filed under: Blogs | No Comments »
Posted on August 26th, 2010 by Brian Kelly
About This Document
The briefing document provides advice on implementing quality assurance processes for the content of your blog, including the establishment of appropriate editorial processes, identification of an appropriate writing style, mechanisms for minimising spam and approaches to ensuring you blog contains quality content.
Quality Process Issues
There are two important quality issues for blogging success – style and content. Readers of your blog will notice poor spelling or grammar, and unstructured ramblings are unlikely to maintain your reader’s attention.
Using the following techniques and tips can help improve the quality of your blog. If you are uncertain about your content or writing style, try working collaboratively with a colleague who is willing to check your material before posting.
Editorial Processes
Most blog sites allow you to save and preview your posts before publishing. Using these functions allows you to reflect on the content and review the spelling, grammar and general ‘readability’ of your post before making it live. It also allows you to see how any embedded media such as slides or videos will appear and whether paragraphs and text are spaced correctly.
Writing Style
A good writing style will help maintain your blog reader base. Blogs are known for their short, informal style that allows for quick, easy scanning of content.
It is very important to check your posts for accuracy in spelling and grammar. Unfortunately spell-check is not a function available on all blog writing pages, so it may help to copy and paste your work into a word processing document to help find errors.
If you have a group or collaborative blog, it may help to set out some guidelines on the feel you want posts to have – will they be formal, informal, lengthy, minimalist, will images be included, how will you reference links and so on. You may also wish to agree on how tags are to be used and standardise them.
Policies On Comments
Deciding whether you will open your blog to moderated or un-moderated comments is another issue for consideration. Think about your audience and the scope of your blog to help with this decision.
Minimising spam is another important quality process. Unfortunately all blogs need to be monitored for spam or inappropriate material, and employing a spam-filter such as Akismet [1] is sensible.
Content Quality
Good content is what makes your audience return to your blog or subscribe to your RSS feed to see when updates appear. Setting down quality measures for the content of your blog helps to build a reader community, and has the added benefit of making it an easier transition for new authors wanting to know what you write about on the blog. Do your posts capture current issues or techniques? Are you relating experiences or activities that will benefit a community of users?
Successful blogs are those which capture the reader’s interest. Many blog authors add small pieces of their lives, outside of the blog topic to personalise their content and help readers relate to the author. However you should first establish a policy which determines whether this is acceptable for your blog.
Once you’ve posted your blog post, standard practice is that it remains unchanged, except for minor typographical changes. If changes are significant or needed to clarify a point, good practice dictates that a note or addendum is added to the original post, or the text font is changed to ‘strike-through’.
Make sure your blog posts are marked with the date and time of posting and, on a multi-author blog, the name of the person posting.
Document Your Processes
It may be useful to outline in your blog policies the quality processes through which your blog will be subjected. Not only does this help with consistency in the content and how it’s presented, but it gives your readers an understanding of the processes your material has undergone before release. As an example, see the UK Web Focus’s blog policy [2] . You may also wish to carry out a periodic evaluation of your blog policies to see whether modifications or enhancements may be appropriate.
References
- Akismet,
<http://akismet.com/>
- Blog Policy, UK Web Focus Blog,
<http://ukwebfocus.wordpress.com/blog-policies/>
Filed under: Blogs | No Comments »
Posted on August 26th, 2010 by Brian Kelly
Background
This briefing document provides advice on planning processes for setting up your blog.
Getting Started
Before you commit to a blog, you need to be sure that a blog is the right tool for the job. Use the checklist below to see if a blog will work for you.
- Blogs are an informal and ‘chatty’ medium
- Blogs can be useful for providing a more personal and friendly face to the world but are not necessarily a good way of presenting formal information. You will probably need content that lends itself to a more personal interpretation. A blog is the place to write about how you survived the fire drill, rather than a place to publish the standard issue health and safety rules on fire drills in public places.
- Blogs are a dynamic medium
- Blogs are designed for readers to comment on the contents of each post, so make sure your material is suitable for this dynamic approach as it is great for getting feedback and ideas, but not so good if comments are really not required. On a library blog, for example, outlining a project for introducing e-books and asking for comments would be fine, but don’t post on something you don’t want public opinions on. A blog will lose credibility if you remove comments or don’t accept reasonable input.
- Decide on whether the blog is to be open access or closed access
- This can change your view of suitable material. Blogging about plans for implementing a new technology, for example, might not be appropriate for a public blog open to end users. But a closed blog available just to staff within your organisation could be a useful tool for keeping everyone up-to-date with progress.
- Is the blog to be about something that requires regular updates?
- If you start a blog but find the subject matter isn’t really changing on a regular basis, and you are struggling to find something to post about, then you haven’t got a blog! Before you commit to blogging, sit down and do a list of ten topics for posts on the themes your blog will tackle. If you can’t easily generate this amount of ideas, you haven’t got a bloggable subject.
- If the blog is open access, decide on an editorial policy for dealing with comments
- There are grades for monitoring comments – from no moderation at all where submitted comments are published without checking to complete authorisation of each comment. Be aware of possible spam postings as well as un-welcome (e.g. rude or abusive) comments and make sure you are in control. If you are promoting an organisation via a blog, be aware that comments are as much a part of the blog as the blogger’s posts. Although you don’t want to stop an exchange of views and thoughts, you do want to make sure you don’t aid in the publication of inappropriate material. A few simple precautions can keep everything running smoothly.
Ongoing Processes
In order to ensure that your blog service is sustainable:
- Ensure that you have regular posts on the blog
- Plan ahead and consider asking someone to be a guest blogger if you are away or too busy to post regularly for any short period of time.
- Consider group blogging with colleagues
- This could work for both an internal, project-based blog and also for a public-facing organisation-based blog. Different bloggers can bring a new perspective to a topic and give the readers a different take on your themes. See a library from the point of view of a cataloguer, a web master, inter-library loans. Get an insight into a museum from the perspective of the curators of different collections or view an archive from the inside. Follow progress on different strands of a project via the technical lead, the project manager and the customer liaison contact.
- Keep your blog fresh
- Don’t forget that the idea of Web 2.0 is to interact and share with your readers, so use the comments section to generate new ideas. Acknowledge the source of your ideas and reference the reader and their comment and you will help your blog community to grow.
- Keep an eye on comment spam
- Remember that as well as the automated spam that can be clearly identified as spam, there may be comments )e.g. “This is a great post”) which have been generated automatically, in order to provide links back to a commercial blog. This is known as ‘blog comment spamming’.
Share Your Planning Processes
You will not be the only cultural heritage organisation which is considering best practices for providing and maintaining a blog service. A good way of validating your planning processes is to share these with your peers and solicit constructive criticism and feedback.
Filed under: Blogs | No Comments »
Posted on August 23rd, 2010 by Brian Kelly
Background
The briefing document provides advice on how to establish a policy for your blog.
Why Outline Your Blog Policies?
Most blog sites and software offer a section for the author to explain a little about themselves and their activities. Developing this section to include the policies by which your blog operates gives a clear message to your readers regarding your purpose and scope, promoting openness and transparency. These policies are useful as a guide, but are not legally binding, and you may wish to take professional advice depending on your circumstances. You may wish to use the following headings as a guide for areas to be included in your blog policy.
The Purpose of Your Blog
It may be useful to outline the purpose of your blog with reference to your organisational mission statement or operational goals. Explain why your blog exists and its aims and objectives, such as to inform library users of new resources or services, or to provide tips and techniques on learning materials for students. Your blog purpose may simply be to offer a voice from the library.
Scope and Target Audience
Outlining the scope of your blog can help focus your posts and tells your readers what to expect. Suggesting a frequency of posts also helps manage your reader expectations.
Specifying your target audience doesn’t exclude other readers, but does help to make explicit who this blog is written for. Examples of target audiences may be your library users, colleagues, students, subject specialists, fellow researchers or simply yourself and your mentor if you are using your blog as a reflective journal.
Licensing Your Blog Posts
In a spirit of cooperation and sharing, many bloggers in the cultural heritage sector add a Creative Commons [1] licence to their blog. The Creative Commons Web site allows you to create a human-readable agreement that allows you to keep your copyright but permits people to copy and redistribute your work whilst giving you the credit.
Details of Quality Processes
Documenting the quality processes undertaken on your blog allows you to make explicit the writing style your readers can expect, any editorial processes involved and how changes to the text are treated. You may wish to provide an overview of how content for the blog is selected or developed. If your blog is personal or reflective, it may be worth providing a disclaimer to represent that the views expressed are strictly your own and do not represent the official stand of your employer.
If you cannot maintain your blog and need to close the service, it is good practice to archive the site and add a disclaimer stating the blog is no longer being maintained.
Comment Moderation and Removal of Material
Comment moderation can range from completely open commenting to requiring approval for each comment. It may help to inform your readers of your settings and to alert them that you reserve the right to archive their comments, or remove them if you feel they are inappropriate or outside the scope of the blog.
Dissemination
If your aim is to share experiences and contribute to a particular community of practice, it may be worth outlining how you plan to disseminate your work. This may signpost companion sources for your peers and colleagues, for example feeding your posts to a Facebook [2] group, or into a social networking site such as the Library 2.0 [3] and Museum 3.0 [4] Ning sites.
Reserving Your Rights
It may be wise to add a disclaimer to your policy document stating you reserve the right to make amendments to your policies at a later date if necessary. This gives you the flexibility to make changes if needed.
References
- License Your Work, Creative Commons, <http://creativecommons.org/license/>
- Facebook, <http://www.facebook.com/>
- Library 2.0, Ning, <http://library20.ning.com/>
- Museum 3.0, Ning, <http://museum30.ning.com/>
Acknowledgements
This briefing document was written by Kara Jones, University of Bath.
Filed under: Blogs | No Comments »
Posted on August 23rd, 2010 by Brian Kelly
About This Document
This document gives ideas for using blogs to enhance services provided by museums.
Blog Can Enhance A Museum’s Image
Museums cannot afford to ignore the community they service. They no longer simply provide a repository of artifacts. Museums need to be seen to serve the community by engaging with the public. Blogs provide an excellent tool for doing this.
Blogs Differ From The Museum’s Web Site
Blogs typically have a different style from the museum’s institutional Web site. They often do not use an institutional tone of voice but are conversational and personal and may consist of many contributors’ voices.
The institution’s Web site is normally accessed for informational purposes, such as factual information about the museum, opening times, access details, etc. Blogs, on the other hand, often provide access to community, which may include museum staff, but also museum visitors and other interested parties. The character of blogs is not necessarily fixed and may evolve depending on the often changing contributors.
Blog posts typically incorporate many links to other blogs, similar interest groups, etc. Such links can also include slide shows, videos on YouTube links, games, and other resources.
Since blogs often have the voice of the enthusiast and encourage discussion and debate they may be more trusted that conventional marketing-focussed Web sites.
Blogs Can Complement The Museum’s Web Site
Blogs can add depth and richness to museums’ descriptions by providing contextual information (“How this exhibition came to be) or a new angle (“Techniques in hanging the new exhibition”).
Blogs can provide an opportunity to get to know the experts (“Day in the life of the education outreach coordinator) or engage with them (“How are works of art lent to other institutions?”). They can build a new audience, often younger (“We would like to see this type of event happening here”).
Blogs can provide new and fresh content on a regular basis (“Charlie Watts seen in the museum looking closely at the Rubens”).
Blogs Are About Communication
Blogs can create a environment of person to person communication by seeking opinions, ideas and feedback and by encouraging the visitors to participate and contribute (“What we think of the new exhibition“) and share experiences (“This series of lectures is great, what do you think?“).
By responding to comments the museum is seen to be listening to its public (“What a good idea to stock this in the shop“). This can help to create an atmosphere of openness and trust.
Problems And Solutions
There can sometimes be opposition from management or colleagues within the organisation. Why is this and what solutions may there be?
- Control
- The use of social media in a museum’s context is concerned with releasing control and ensuring that knowledge is not only in the hands of the curators. However there are many examples of the public contributing additional and hitherto unknown information about a museum object. The advice: “Just relax and try it!“.
- Resources
- Maintaining blogs can be seen as a drain on resources, both human and financial. However, a system of regular contributors who post their own articles in a structured schedule only require overseeing. Each deals with their own related comments. The technology can be cheap. Advice on best practices for using blogs (and other Web 2.0 technologies) is available from the UKOLN Web site [1].
- Contributions
- There may be difficulties in finding contributors within the museum. Look wider – children who use the educational facilities, local artists who come for inspiration, the people who serve in the cafe, Friends, Trustees. This provides a variety of different voices and engages new communities.
References
- Briefing Documents for Cultural Heritage Organisations, UKOLN,
<http://www.ukoln.ac.uk/cultural-heritage/documents/>
Acknowledgments
This briefing document was written by Ingrid Beazley, Dulwich Picture Gallery based on a Blogging workshop facilitated by Brian Kelly (UKOLN) and Mike Ellis (Eduserve) at the Museums and the Web 2008 conference.
Filed under: Blogs | No Comments »
Posted on August 23rd, 2010 by Brian Kelly
About This Document
The briefing document provides suggestions for ways in which blogs can be used to enhance the services provided within libraries.
Blogs Can Help To Communicate With Your Library Users
Librarians have long used a variety of means for getting information about the library out to our communities – newsletters, alerts, emails, posters and flyers and more.
Using a blog offers the opportunity to innovate your communications. Blogging gives you a way to push information out, but also to gather feedback and build a community without having very much technical know-how.
Types of Blogs
Blogs can be personal or professional. They may be private with use internally in an organisation or they may be publicly available – this is controlled by the settings on your blog site.
Blogs can be individual, group or subject blogs. An individual blog is a personal blog reflecting the thoughts of one person. A group blog is a collective effort written by a team or organisation, and a subject blog is written by any number of people, and is focused on a particular topic[1].
Once you have decided on the blog’s purpose think about which of these different approaches will work best for you. You may also like to think about developing a set of blog policies to help outline the blog’s scope, and focus your target audience.
Ideas For Using Blogs
The following provides a few ideas for blogging in your library. This is just a small selection – blogs are very versatile and there are many more practical applications.
- News gathering and dissemination:
- Blogs provide a useful way for librarians to disseminate small snippets of information to their library users. A subject librarian in an academic library might find it useful to gather database updates, new site and service notices and event information in the one place on a blog.
- From the librarian’s desk:
- Blogging about your daily work gives your library users an insight into your roles and responsibilities. It helps to provide openness and transparency, whilst informing of library news and events.
- Community building:
- As librarians we are part of a group of professionals that benefit from the sharing of good practice and experiences. Blogs can be a very timely way to offer advice and commentary on current library issues.
- Library resources:
- Raise the profile of the resources in your library by blogging about their features. If you have a collection of resources for speakers of other languages, why not invite a few people using these materials to blog about them, and build an online community.
- Special projects:
- Are you building a new library, refurbishing a new section, or other library developments that are visible to your library community? Blogging about the project will allow your users to engage in the project and become involved in decision making, and photos or videos of progress can add interest to your blog.
- Task groups:
- Use a blog to capture and collect the thoughts of members involved in a task group. Blogs have built in archive features to record your work and tagging can be used to categorise sections.
- Reflective journaling:
- Blogs don’t have to be public affairs. Think about your own professional development and chronicle your activities on a blog. It’s amazing how a few minutes spent reflecting on your daily activities adds up so you can see a path of progression and achievements. If appropriate, share these thoughts with your colleagues so they also have a record of your activities.
Getting Started with your Library Blog
Blogs can be as resource and time intensive as you make them. Deciding to use a blog to communicate with your users allows you to be as creative or serious as you like.
There is a wealth of information and advice available especially for librarians wishing to investigate blogging: read other briefing papers, join mailing list such as lis-bloggers [2] or participate in services aimed at the blogging librarian community.
References
- Blogging and RSS: A Librarian’s Guide. Sauers, M.P. 2006. New Jersey. Information Today
- lis-bloggers, JISCMail, http://www.jiscmail.ac.uk/lists/LIS-BLOGGERS.html>
Acknowledgements
This briefing document was written by Kara Jones, University of Bath.
Filed under: Blogs | No Comments »
Posted on August 23rd, 2010 by Brian Kelly
About This Document
This briefing document provides an introduction to blogs and key blogging tools and concepts.
What Is A Blog?
A blog (a portmanteau of web log) can be simply described as a Web site where entries are written in chronological order and commonly displayed in reverse chronological order.
A typical blog combines text, images, and links to other blogs, Web pages and other media related to its topic. The ability for readers to leave comments in an interactive format is an important part of many blogs.
Providing A Blog
Blogs can be provided in a number of ways. Blog software can be installed locally (open source or licensed), or blogs can be deployed using an externally hosted service (Blogger.com and WordPress.com are popular).
In an organisation or educational institution you may find tools provided by existing systems (e.g. a VLE, a CMS, etc.) which have blog functionality provided. Alternatively, many social networking services (e.g. Facebook, MySpace, etc.) provide blogging or similar functionality.
Reading Blogs
A key strength of blogs is that they can be accessed and read in a number of ways. Blog readers can take the conventional approach and visit the blog Web site using the Web address. New posts on a blog can be read using an RSS reader. These readers can be Web-based (e.g. Bloglines, Google Reader, etc.) or a desktop RSS reader (e.g. Blogbridge). If you read a number of blogs, you may wish to use a blog aggregator, which allows you to view posts from lots of blogs in one place or have subscribe to have blog posts delivered to your email. Blogs can be accessed by using a mobile device such as a PDA or mobile phone.
Blog Features
There are some features which are standard on most blog services:
- RSS or Atom Feeds
- Feeds are small snippets of XML that allow you to subscribe to a blog and have updates or new posts sent to your desktop automatically. This is useful is you have a number of blogs to keep up with, as you can read a number of feeds in one place using an RSS aggregator or feed reader.
- Tags/Categories
- Tags are similar to subject-headings or category words given to a post. A blog author can create as many or as few tags as they like. A collection of tags displayed as words of differing sizes is called a tag cloud. Tags may also be called ‘labels’ or ‘categories’.
- Blogroll
- A blogroll is a list of blogs that the author of the blog has favourited or reads regularly. The links on a blogroll are a great way to find new blogs, often on a similar topic to the blog you are currently viewing.
- Comments
- Many blogs have a comment function which allows readers to provide feedback on the post. Comments may be moderated by the blog owner and can be configured so that readers may need to be registered or they may be anonymous.
- Archive
- Most blog sites will automatically archive posts, usually by month. This helps to keep blog pages reasonably short and tidy.
- Widgets
- Blog sites may display widgets, often in a sidebar, which may provide additional functionality on a blog site.
Finding Blogs
Finding blogs on a particular topic can be a challenge. Try using Technorati [1] or Google Blog Search [2] which are search engines for blogs, or similar blog directories. Many good blogs are found by recommendation, such as inclusion in the blogroll of a topical blog or reviewed in the literature.
References
- Technoratori, <http://www.technorati.com/>
- Google Blog Search, <http://blogsearch.google.com/>
Filed under: Blogs | No Comments »
Posted on August 23rd, 2010 by Brian Kelly
What Is Web 2.0?
Web 2.0 is a term which is widely used to describe developments to the Web which provide an emphasis on use of the Web to provide collaborative and communications services, as opposed to a previous environment in which the Web was used primarily as a one-way publishing tool.
Web 2.0 also refers to a number of characteristics of this pattern of usage including a richer and easy-to-use user interface, delivery of services using the network, continual development to services, the social aspect of services and a culture of openness.
Criticisms Of Web 2.0
It should be acknowledged that the term ‘Web 2.0′ has its critics. Some dismiss the term as ‘marketing hype’ whilst others point out that the term implies a version change in the underlying Web technologies and some argue that the vision described by the term ‘Web 2.0′ is little different from the original vision of Tim Berners-Lee, the inventor of the World Wide Web.
In addition to these criticisms of the term ‘Web 2.0′ others have doubts concerning the sustainability of Web 2.0 services. The use of externally-hosted Web 2.0 services has risks that the service may not be sustainable, that its terms and conditions may inhibit or restrict the ways in which the service may be used and that social networking services may be inappropriate for use in a work context and may infringe personal space.
Using Web 2.0 Effectively
Although the criticisms have an element of truth, and it is also true that Web 2.0 can be used purely for its hype value, it is also true that many Web 2.0 services are very popular with large numbers of users. Organisations which seek to exploit the benefits of Web 2.0 should be mindful of the need to address their potential limitations such as the sustainability of the services; accessibility challenges; dangers of a lack of interoperability; privacy and legal concerns; etc.
Web 2.0 Technologies
The main technologies which are identified with the term ‘Web 2.0′ are:
- Blogs
- Typically Web pages provided in date order, with the most recent entry being displayed first. Blog tools produce RSS, which allows the content to be read via a variety of tools and devices.
- Wikis
- Simple collaborative Web-based authoring tools, which allow content to be created and maintained by groups without needing to master HTML or complex HTML authoring tools.
- RSS
- The Really Simple Syndication (RSS) format allows content to be automatically integrated in other Web sites or viewed in applications, such as RSS readers. A key feature of RSS readers is the automatic alerts for new content.
- Podcasts
- Podcasts are a type of RSS, in which the content which is syndicated is an audio file. New podcasts can be automatically embedded on portable MP3 players.
- AJAX
- The user interface of many Web 2.0 applications is based on a technology called AJAX, which can provide easier to use and more intuitive and responsive interfaces than could be deployed previously.
Web 2.0 Characteristics
The key characteristics of Web 2.0 services are:
- Network as platform
- Rather than having to install software locally, Web 2.0 services allow applications to be hosted on the network.
- Always beta
- Since Web 2.0 services are available on the network, they can be continually updated to enhance their usability and functionality.
- Culture of openness
- A key benefit of Web 2.0 is provided by allowing others to reuse your content and you to make use of others’ content. Creative Commons licences allow copyright owners to permit such reuse. This has particular benefits in the cultural heritage sector.
- Tagging
- Rather than having to rely on use of formal classification systems (which may not be meaningful to many users) tags can be created by users. The tags, which may also be meaningful to their peers, provide communal ways of accessing Web resources.
- Embedding
- Many examples of Web 2.0 services allow the content to be embedded in third party Web sites, blogs, etc.
Filed under: Web 2.0 | No Comments »
Posted on August 22nd, 2010 by Brian Kelly
This blog is being used to generate RSS feeds for UKOLN’s cultural heritage briefing documents.
Filed under: Uncategorized | No Comments »
