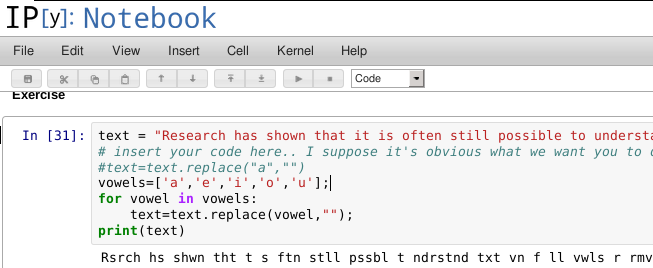
I’m no SQL Expert
Over the past few years I have had my fair share of tricky data management opportunities. There was the financial transaction database that had no keys or indexes and had to be pieced back together by getting old source code releases, finding the bugs and reversing the incorrect values. There was the GB’s of web log records that needed cross referencing and finally, analysing free text marketing responses for patterns.
This was all a warm up for my current opportunity. With this task I have all the issues at once. I have the scale, with 22 million odd items. I know it’s not enormous for 2012, but it is far from easily manageable. I have the lack of consistent relationships and the final piece of the puzzle lack of data quality.
What I wouldn’t give for a nice enumeration of types, something concrete to go on. Take dates for example. For decades it has been the norm to store dates in ISO format, or at least something that can be converted back and forth. If I am really lucky I get ISO dates, a lot of the time I get something that isn’t defined but recognisable and can convert to ISO from, for example, ‘moon cycles since equinox format’ ™. Often though, I get user typed input, not from the same person and not even the same system. Entering dates like “about the middle of last year” is guaranteed to anger even your most friendly neighbourhood developer.
Taken individually it isn’t that big a deal. However producing results in reasonable web- response speeds for 22 million records, grouping by, counting and cross referencing on thousands of possible groups on standard hardware is eluding me. If you can make them dance this way I would love to hear from you.
NoSQL Hype vs. Substance
I’m sure I am not the only one who has trouble keeping up with the latest and newest technology releases. There are lots of exciting new cool apps and services that I don’t really have the time to investigate due to the sheer quantity. Sometimes I just don’t have the patience to coax a demo app out of the latest beta release, constantly cross referencing against error messages. Finally, my least favourite, there is the kind of technology forced along by big business marketing.
Data storage is huge business, particularly the other side of the Atlantic. There are vast sums of money at stake and even corporate survival can depend on the success or failure of given products. I’m no Commie, I don’t mind this in principal, but the amount of positioning, media attention and misinformation that then surrounds the products makes it very hard to separate the hype and the substance.
A couple of weeks ago I was deliberating, remembering all the great things I have heard about NoSQL. Maybe the NoSQL people have a point and now I have a solid use case where my RDBMS is not suiting me. Up until this point I had discounted alternatives to my RDBMS on the grounds that any storage solution was moving bits around on a disc and that the same rules applied. Like all performance computing it is a game of caching. Keep indexes in memory and look to disc as little as possible. Indexes and disc space usage are always going to be more or less equal leaving any performance improvements to the implementation, hardware and possibly some new algorithms. RDBMS design was based on set theory and predicate logic, or to put it another way, Maths. Very little has changed to satisfy my scepticism with regards the speed and scale increases promised by NoSQL movement. Even the idea that there is seen to be a movement worries me. I mean, it’s hardly suffrage, anti-war or civil rights is it?
Some are more NoSQL than others
Up until now I have been talking about NoSQL as a single entity. Of course this is just one of the misleading factors. For some reason, lots of substantially different technologies have been lumped under one umbrella. Maybe the daunting numbers necessitated this; maybe it was because it was felt they could survive better as a combined opponent to RDBMS. The majority of them share some common themes but thinking of them as a single entity is particularly unhelpful. In fact several of the so called NoSQL solutions have more in common with your SQL RDBMS than each other. Two of these notable exceptions are CouchDB and Neo4 which offer ACID compliance.
From Wikipedia the generally accepted types of NoSQL solution are -:
Document store, graph, Key-value store, multivalue, object, RDF, tabular and tuples
Having read a few articles about the various NoSQL solutions, it seems that each author had decided to group them up and talk about the groups in some way, for each offering possible scenarios where each are useful. So far it has been easy to pick holes in every one of the lists, in some cases because they are out of date but mostly because even in these sub types the feature sets can still be very different. For this reason I shall approach this from a slightly different angle. Firstly I shall talk about common themes to most (but not all) of the NoSQL solutions, then follow up with a few types of software and which specific NoSQL products would be useful.
Speed and ACID
Earlier I mentioned that I couldn’t really see how you can develop a significantly faster comparable version of a storage solution. In the case of the majority of the NoSQL products, the main selling point is horizontal scalability. To put it another way, it is easier to deploy over lots of load balanced clusters giving the performance gains. DBRMS’s do not scale as easily in this manner.
The reason for this is that all good RDBMS’s are at least approaching ACID compliance. In essence, this is your guarantee that data you store is consistent and will be there when you want it. With ACID comes the concept of transactions which are important for many real world tasks, and without them bank transfers would vanish, nuclear missiles would launch. The locking required does not work as easily over RDBMS clusters due to the inevitable latency.
Having said that there are many cases where this isn’t important. You could maintain the consistency at the application level. It gets increasingly harder to maintain with increasing system complexity but it is far from impossible. Alternatively read only data sources are a good candidate or maybe you just don’t care. If the odd ‘Like’ or +1 goes missing the sun will still rise the next day. In addition I should probably point out that most people tend to agree that NoSQL means ‘Not Only SQL’. For reasons discussed, in most cases it would represent part of a given solution. A fast NoSQL solution would work well as a client facing readable resource to a large complex dataset.
NoSchema
A relaxed or in some cases entirely non-existent schema is another selling point. This for me is the key difference. So many times my model has altered slightly and various null checks have crept into my code. You can easily see how in some cases a very relaxed schema would be a nice thing to have.
Commodity computing
Computing as a commodity has been a big driver behind many of these products. It isn’t hard to see the value of being able to easily spin up a few more database clusters over the Christmas busy period with little fuss. This is a key feature of how the horizontal scalability can be a massively appealing part of these solutions. Taking this further some products have an emphasis on distribution. For example you could have a country or regional presence in a datacentre where for example UK residents are served by one cluster/shard and Australian by another. Maybe you can offload your Black Friday North American rush to your Pacific Rim cluster where it is 2am.
UC1: Online Store/CMS/Blog
If you though there were a lot of NoSQL options then you are in for treat when you start looking for a CMS. It seems that every developer, has at some point, started coding their own CMS. It isn’t hard to see that document stores are particularly suited to this task. Almost the entire focus is around the document. Taking a real world example, MongoDB and Etsy demonstrate a nice scenario for this use case. On Etsy you have various sellers all over the globe creating product pages. Some might have shipping restrictions, photos, size guides, linked products or any number of combinations. With MongoDB and a relaxed schema, a product page could be a single document with just the relevant categories embedded. I am willing to bet they don’t use it for their payment systems though.
UC2: Caching
Memcached is probably the most common and famous example of caching in the NoSQL world*. Notoriously thousands of memchached nodes allow us all to keep up with the interesting happenings on Facebook. These are typically used in front of a backing data store and provide most recently used hash based caching and runs entirely from RAM. I think they key here is understanding that it can be used as part of a massive infrastructure rather than being something particularly revolutionary.
If you aren’t Facebook or similar and thinking of adding one memchached box to the font a box or two, you might be better off exploring other routes first.
*Other k-v stores are available.
UC3: Development
A relaxed and adaptable schema during software development has obvious benefits.
UC4: Graph Data
The most interesting type of solution in my opinion is the Graph database and oddly this seems to be the direction that receives the least attention. I have had a number of problems where I needed to view data from various angles at different times and the relational approach just didn’t work. I was constantly creating temporary tables of underlying data from different directions which became hard to maintain. Expressed as a graph I can see that it could be far easier to work with. Again the concept of data as a graph is hardly new but I am about to trial Neo4j as a solution to my current problem so I shall report back with my findings.
UC5: Analytics
The likes of Hadoop MapReduce can be suited to analytics. Typically reporting makes it into the code at a much later stage and can be easily forgotten. I have seen many systems spending most of their cycles calculating the nightly sales reports with increasingly complicated SQL queries over their perfectly normalised data sets. Aggregating, result summarisation and general querying can be guaranteed with real time performance. Google, despite trying to replace it, are using a version of this behind the scenes to provide your search results. It clearly scales.
I’m no NoSQL Expert
It is a point worth labouring, that the key is in picking the right tool for your data. Slightly less obviously it is about how you need to reference that data, not only today but in the future.
Experiences
Being a developer I had itchy keyboard fingers and didn’t quite get around to researching thoroughly before I trialled MongoDB. Seemingly it was a good match for my data with a relaxed schema but there probably isn’t a worse match for my need to referencing the data. Lesson learnt until the next time. Had I not experimented though I would not have had the joy of expressing my MapReduce functions inside a Mongo query using JavaScript. Whose idea was that?
I am still evaluating Hadoop, the pinup for NoSQL. I think there is a lot of potential here for MapReduce in my batch operations, a clear fit, but there is considerable set-up overhead. The Hadoop umbrella has also become quite sizeable in its own regard so I expect there is some more value in this area. Neo4j is also looking very promising. It is a Graph based ACID database and as such stands out. Relationships are treated, according to the documentation, as first class citizens so I am taking a look at this next. My only concern is how it performs with ad-hoc queries. Failing all this I will go back to multi pass batch processing on my RDBMS with plenty of caching for good measure. It’s not elegant, but it works.
]]>