
Extended Repository PDF Assessment
As part of FixRep a small project is being carried out to examine the use of metadata in pdf documents held in HE/FE repositories (such as the University of Bath’s Opus repository). This builds on an initial pilot that was carried out using pdfs harvested from Opus, which we wrote a paper about for QQML 2010 (Hewson & Tonkin, 2010).
The original study of Opus was an exploration to test out the extraction and analysis process. Obviously the initial analysis focusing on only one repository could only be used to draw conclusions about what’s in Opus; issues it may present, metadata usage, etc. The extended assessment is examining pdfs from about a dozen UK repositories so that a reasonable analysis of metadata, comparison of ‘standard’ usage, and common vs. unique issues, can be obtained.
So, how are we going about this?
It’s a pretty manual process at the moment, at least each of the stages is kicked-off manually, and can be divided into three stages…
- Harvest the pdf files
- Extract the metadata into database
- Analyse content
Harvest…
Using wget the repository structure containing the pdf files is copied to a local server. This process takes some time and can be rather heavy-handed in the overhead it places on the repository server through continual requests for files. If we wanted to extend the extraction and analysis process into a service that regularly updates, then a more considerate approach towards the repositories would be required. However, we’ve got away with it at least this far!
Extract & load…
A prototype service that extracts information from pdf documents was developed as part of the FixRep project. It extracts the information in a number of ways:
Heading and formatting analysis, such as:
- The version of the PDF standard in use
- Whether certain features, such as PDF tagging, are declared to be in use
- The software used to create the PDF
- The publisher of the PDF
- The date of creation and last modification
Information about the body of the documents:
- Whether images or text could be successfully extracted from the document and, if they could, information about those data objects.
- If any text could be extracted from the object, further information such as the language in which it appeared to be written and the number of words in the text
Information from the originating filesystem, such as:
- document path
- document size
- creation date, etc.
The extracted information is put into intermediate files in an XML format and is then loaded into a MySQL database for…
Analysis…

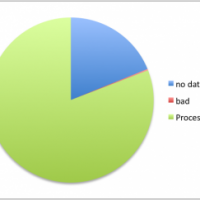
PDF Processing
The first thing we actually look at is how many of the harvested pdf files could be processed, and for those that failed, what was the reason they failed. For example in out pilot run against the Opus content about 80% of pdf files could be processed. The 20% that failed were mainly due to the service being unable to extract meaningful information, while a very small number of files turned out to be ‘bad’ pdfs – that is the format of the files was corrupted or not in a recognisable file format. some of the errors identified were recoverable with some manual intervention, while some meant file had to be excluded as un-processable.
While not definitive, this does give us a baseline expectation for the success rate of extracting meaningful information from other repositories.
Once we have the data in the database it’s easy enough to run some sql to generate simple statistics such as: Type and number of distinct metadata tags used; Average number of metadata tags per file; etc. This gives us a good overview of the content (in a given repository) and whether the content is consistent within and between repositories.
Next steps…
The target repositories have been harvested and will soon be processed for analysis. So, unless some very unexpected processing problems happen we should have results and be ready to produce a report on this project in early December.